A High Level Framework for thinking about Task-Specific Evaluations for LLMs

Introduction
Evaluation frameworks serve as crucial tools for measuring performance and driving improvements in the rapidly evolving field of AI. This post aims to clarify the often misunderstood concept of task-specific evaluations, providing a clear framework that practitioners can apply to their own systems.
This will be a part of a series of blog posts on the topic, cataloging what I’ve learned building with AI in the past couple of years.
Defining the Evaluation Space
When approaching AI evaluation, we can broadly categorize our approaches into two distinct types:
- Task Specific Evals: Focused on evaluating the input-output relationship (
f(x) = y) for specific tasks - Agentic Evals: Concerned with evaluating the quality of conversation turns, tool selection, topic handling, and other interaction dynamics
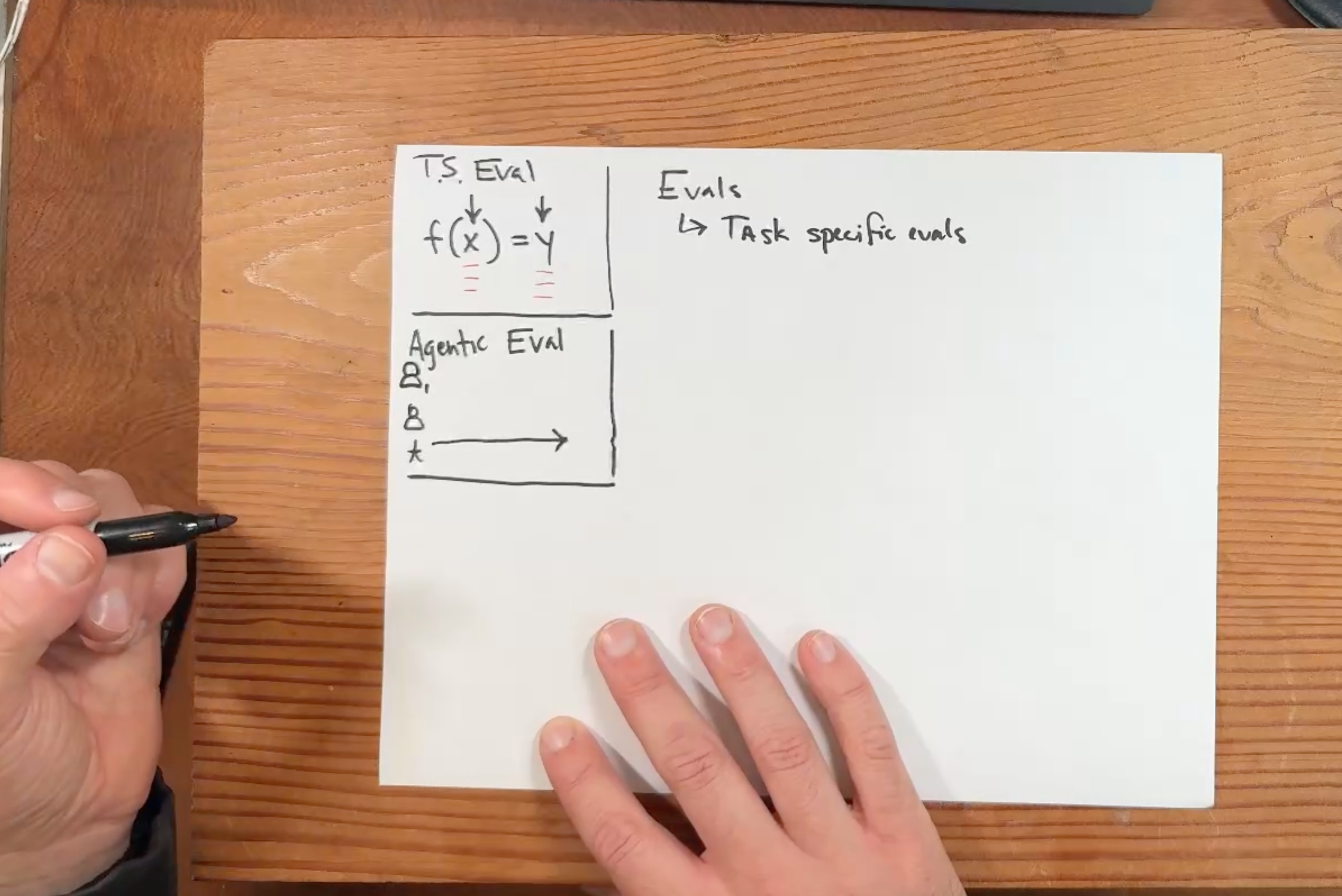
While both are important, this post will focus exclusively on task-specific evaluations. The goal of this post is just to explain some basic ways of thinking about task-based evals and why automatic prompt tuning might be a good idea.
The Pseudo-Mathematics of Task Specific Evals
At its core, a task-specific evaluation can be understood through a simple algebraic relationship:
y = ax
Where:
xis our input (which could be a string, dictionary, number, or any data type)yis our desired output (similarly flexible in type)ais our transformation function (in practical terms, our prompt template)
This framework mirrors the familiar y = ax + b from high school algebra, though we can typically simplify by assuming b = 0 for our purposes.

The prompt template will be rendered,
from jinja2 import Template
template = Template("Hello, {{ name }}!")
output = template.render(name="World")
print(output)The Prompt as a Transformation Function
The key insight is that task-specific evaluation is fundamentally about tuning the “A” value-our prompt template-to consistently transform inputs into desired outputs. This tuning process can be:
- Manual: Progressively refining prompts based on observed outputs
- Automated: Using tools like DSPy, AdalFlow, or Task LLM to systematically optimize prompts
The best process is probably a combination of the two.
Practical Example: The Joke Evaluator
Consider a simple example where we want to evaluate humor:
Template: "Is this joke funny: {joke}?"
Input (x): "Why did the chicken cross the road? To get to the other side."
Output (y): "Yes" or "No"Our transformation function A is the prompt template that takes the joke as input and produces the evaluation as output.
Applying to more Complex Systems
The same principles apply whether you’re dealing with a single prompt or a chain of prompts. For example, a query like “Are the Warriors playing this week?” (it’s NBA playoffs) might decompose into:
- Component 1: Search term generation
- Component 2: take search engine responses and combine them into a single response.
The key insight here is that this prompt sequence is a ‘node’ and we can decompose that node into its sub-nodes.
Each component can be evaluated and tuned individually, or the entire chain can be treated as a single unit. The flexibility of this approach allows for precise identification of failure points within your system and improving / testing the overall system as whole.
Why Instrumentation Matters
Breaking down your system this way is critical for:
- Localized debugging: Identifying exactly where problems occur
- Targeted optimization: Focusing tuning efforts on problematic components
- Performance measurement: Establishing clear metrics for each transformation step
Conclusion
Task-specific evaluations offer a powerful framework for understanding, measuring, and improving AI systems. By conceptualizing your prompts as transformation functions that convert inputs to outputs, you can systematically identify weaknesses and implement improvements.
Whether you’re working with simple classifiers or complex chains of reasoning, the fundamental approach remains consistent: tune your transformation functions to reliably produce the outputs you want given your inputs. This does extrapolate to agents, but that’s a post for another day.
The next time you’re designing an evaluation system, consider how you can apply this framework to create more targeted, effective assessments of your AI’s performance.
In the next posts, I’ll be diving a bit more into the detail on all of this and how to think about evals for your applications.