Guiding LLM Output with DSPy Assertions and Suggestions
Guiding LLM Output with DSPy Assertions and Suggestions
If you would rather watch this, you can find it on our youtube channel - give us a sub and 👍. You can find the code on our github repo - give us a ⭐️.
If you like this content, follow me on twitter and sign up for the newsletter. I’m posting all the time about DSPy and providing a lot of “hard earned” lessons that I’ve gotten from learning how to build with AI from RAG, to DSPy and everything in between.
Introduction
As powerful as LLMs like GPT-3 and Chinchilla are, they can sometimes struggle with hallucinations, factual inaccuracies, and outputs that don’t quite align with your requirements. This is where DSPy’s assertions and suggestions come into play.
btw, read the full research paper on DSPy Suggestions / Assertions here.. Although the below will give you the gist for how to use it in your app.
Assertions in DSPy allow you to define strict rules and constraints that the LLM’s output must (or maybe that you just want) to adhere to. For example, you can use assertions to ensure that the generated text doesn’t contain certain “bad” words, or that the output conforms to a specific structure or format.
Suggestions, on the other hand, provide a more flexible way to guide the LLM’s output. Instead of hard-failing when a constraint is not met, suggestions offer feedback and guidance to the model, allowing it to refine its response and try again.
By leveraging these features, you can:
- Ensure Output Quality: Assertions and suggestions help you maintain high standards for the content generated by your LLM, reducing the risk of hallucinations or factual errors.
- Conform to Specific Requirements: Whether you need to generate text that follows a certain tone, style, or format, assertions and suggestions make it easier to tailor the LLM’s output to your needs.
- Improve Reliability: By providing clear feedback and guidance to the LLM, you can help it learn and improve over time, making it more reliable and consistent in its responses.
In this blog post, we’ll walk through practical examples of how to implement assertions and suggestions in your own DSPy-powered applications. By the end, you’ll have a solid understanding of these features and how to leverage them to get the most out of your LLMs.
So, let’s dive in and start guiding the output of your language models with DSPy!
Setting up the Environment
Before we dive into using DSPy assertions and suggestions to guide the output of large language models, let’s first set up our environment. This will ensure we have all the necessary components in place to get started.
First, we’ll load the autoreload extension, which will automatically reload any changes we make to our code during development:
%load_ext autoreload
%autoreload 2Next, we’ll load the environment variables from a .env file, which is a common way to store sensitive information like API keys:
from dotenv import load_dotenv
load_dotenv()38: Now, we can configure our DSPy environment to use the OpenAI GPT-3.5-Turbo language model. We’ll set the maximum number of tokens to 1000. I’m specifying the api_base because I’m using LightLLM.
import dspy
turbo = dspy.OpenAI(model='gpt-3.5-turbo', max_tokens=1000, api_base="http://0.0.0.0:4000")
dspy.settings.configure(lm=turbo)The basic dspy Pipeline
At the core of DSPy is the concept of Signatures, which define the input and output fields for a given task or module. These Signatures serve as the foundation for DSPy apps.
Let’s start with a simple example of using a DSPy Predict module to generate a greeting based on a given context:
context = "Provide a greeting!"Then we can define our signature.
v1 = dspy.Predict("context -> greeting")
print(v1)Predict(StringSignature(context -> greeting
instructions='Given the fields `context`, produce the fields `greeting`.'
context = Field(annotation=str required=True json_schema_extra={'__dspy_field_type': 'input', 'prefix': 'Context:', 'desc': '${context}'})
greeting = Field(annotation=str required=True json_schema_extra={'__dspy_field_type': 'output', 'prefix': 'Greeting:', 'desc': '${greeting}'})
))This Signature specifies that the input is a context field and the output is a greeting field.
With the Signature defined, we can now use the forward method of the v1 Predict module to generate a greeting based on the provided context:
print(v1.forward(context=context).greeting)This will output:
Hello! How can I assist you today?Nothing crazy.
This simple example demonstrates the basic structure of a DSPy pipeline, where we define a Signature, create a module that conforms to that Signature, and then use the module to generate output based on some input. In the next sections, we’ll explore how to use DSPy’s assertion and suggestion features to further guide and refine the output of our language models.
Implementing assertions and suggestions
In DSPy, assertions are a powerful tool for enforcing strict requirements on the output of your models. They allow you to define specific criteria that the generated output must meet, and DSPy will automatically handle the process of providing feedback and guidance to the language model to help it refine its response.
Let’s look at an example of how we can use assertions to ensure that the greetings generated by our MakeGreeting module do not contain any “bad” words or phrases. We’ll start with a simple implementation:
class MakeGreeting(dspy.Module):
def __init__(self, invalid_greetings = []):
self.invalid_greetings = invalid_greetings
self.prog = dspy.ChainOfThought("context -> greeting")
def forward(self, context):
return self.prog(context=context)This basic MakeGreeting module uses a ChainOfThought model to generate a greeting based on the provided context.
MakeGreeting().forward(context)Prediction(
rationale='produce the greeting. We need to consider the time of day, the formality of the situation, and the relationship between the speaker and the listener.',
greeting='Hello!'
)Now let’s take it to the next level. We’ll start with suggestions - we keep the same code structure but we’re going to modify our forward method.
class MakeGreeting2(dspy.Module):
def __init__(self, invalid_greetings = []):
self.invalid_greetings = invalid_greetings
self.prog = dspy.ChainOfThought("context -> greeting")
def forward(self, context):
result = self.prog(context=context)
_greeting = result.greeting
print(_greeting)
greeting_violations = list(filter(lambda x: x.lower() in _greeting.lower(), self.invalid_greetings))
print(greeting_violations)
formatted = ", ".join(greeting_violations)
dspy.Suggest(not bool(greeting_violations), f"Greetings like {formatted} are so bad, provide a different greeting.")
return resultLet’s run it
g2 = MakeGreeting2(invalid_greetings=['hello']).activate_assertions()
g2.forward(context)ERROR:dspy.primitives.assertions:[2m2024-05-20T21:44:06.846620Z[0m [[31m[1merror [0m] [1mSuggestionFailed: Greetings like hello are so bad, provide a different greeting.[0m [[0m[1m[34mdspy.primitives.assertions[0m][0m [36mfilename[0m=[35massertions.py[0m [36mlineno[0m=[35m111[0m
Hello!
['hello']
Good morning!
[]
Prediction(
greeting='Good morning!'
)What’s happening here?
When the MakeGreeting2 module generates a greeting that contains the word “hello” (which we’ve defined as an “invalid” greeting), DSPy’s assertion mechanism kicks in.
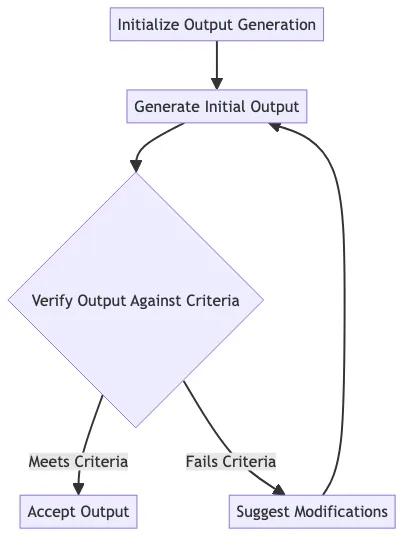
Here’s what DSPy is doing under the hood - we’re building a feedback loop.
 {class=“xs:w-full w-1/2 mx-auto block border-2 border-gray-200 rounded-lg”}
{class=“xs:w-full w-1/2 mx-auto block border-2 border-gray-200 rounded-lg”}
It detects the violation, and instead of simply returning the problematic output, it triggers a “SuggestionFailed” error (this shows up in our console as an error BUT the program keeps running.)
This error message provides valuable feedback to the language model, including the specific instructions on what it needs to do differently (“Greetings like hello are so bad, provide a different greeting.”). We define that feedback, which is extremely powerful.
DSPy then dynamically modifies the signature of the MakeGreeting2 module, adding these instructions and the previous output that failed the assertion. This updated signature is then passed back to the language model, giving it a chance to try again with the new guidance.
The process continues, with DSPy providing feedback and the language model refining its output, until the assertions are satisfied or the maximum number of retries is reached. This backtracking mechanism is a key part of how assertions work in DSPy, allowing the system to iteratively guide the language model towards the desired output.
If you want to see all the details run…
turbo.inspect_history()Given the fields `context`, produce the fields `greeting`.
---
Follow the following format.
Context: ${context}
Past Greeting: past output with errors
Instructions: Some instructions you must satisfy
Greeting: ${greeting}
---
Context: Provide a greeting!
Past Greeting: Hello!
Instructions: Greetings like hello are so bad, provide a different greeting.
Greeting:[32m Good morning![0m
'\n\n\nGiven the fields `context`, produce the fields `greeting`.\n\n---\n\nFollow the following format.\n\nContext: ${context}\n\nPast Greeting: past output with errors\n\nInstructions: Some instructions you must satisfy\n\nGreeting: ${greeting}\n\n---\n\nContext: Provide a greeting!\n\nPast Greeting: Hello!\n\nInstructions: Greetings like hello are so bad, provide a different greeting.\n\nGreeting:\x1b[32m Good morning!\x1b[0m\n\n\n'By using assertions in this way, we can ensure that the greetings generated by our MakeGreeting module adhere to our specific requirements, without having to manually filter or post-process the output. This makes the development of our agent application more streamlined and robust.
In the next section, we’ll explore how we can take this concept even further by using DSPy’s “suggestions” feature, which provides a more flexible way of guiding the language model’s output.
Exploring Assertions
In the previous section, we created a suggestion. In this section, we should explore assertions. This will give us the same output, it’s just using an Assertion as a requirement now.
class MakeGreeting3(dspy.Module):
def __init__(self, invalid_greetings = []):
self.invalid_greetings = invalid_greetings
self.prog = dspy.ChainOfThought("context -> greeting")
self.prev_greetings = []
def forward(self, context):
result = self.prog(context=context)
self.prev_greetings.append(result.greeting)
_greeting = result.greeting
print(_greeting)
greeting_violations = list(filter(lambda x: x.lower() in _greeting.lower(), self.invalid_greetings))
print(greeting_violations)
formatted = ", ".join(greeting_violations)
dspy.Assert(not bool(greeting_violations), f"Greetings like {formatted} are so bad, provide a different greeting.")
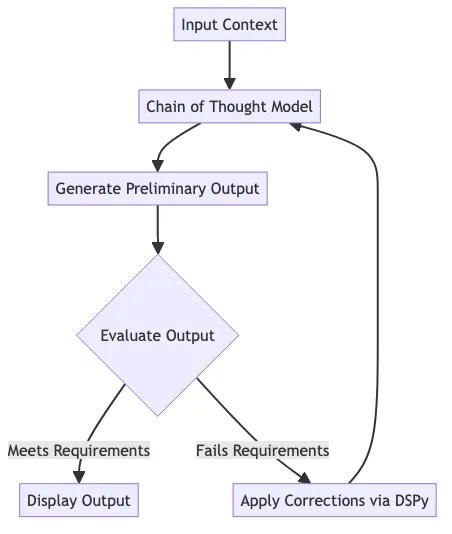
return resultHere’s our flow:
 {class=“xs:w-full w-1/2 mx-auto block border-2 border-gray-200 rounded-lg”}
{class=“xs:w-full w-1/2 mx-auto block border-2 border-gray-200 rounded-lg”}
Now we can run it.
g3 = MakeGreeting3(invalid_greetings=['hello']).activate_assertions()
g3.forward(context)ERROR:dspy.primitives.assertions:[2m2024-05-20T21:46:54.706898Z[0m [[31m[1merror [0m] [1mAssertionError: Greetings like hello are so bad, provide a different greeting.[0m [[0m[1m[34mdspy.primitives.assertions[0m][0m [36mfilename[0m=[35massertions.py[0m [36mlineno[0m=[35m88[0m
Hello!
['hello']
Good morning!
[]
Prediction(
greeting='Good morning!'
)In this case, the model first generated “Hello!”, which triggered a suggestion to avoid that greeting. It then generated “Good morning!”.
We can further refine this approach by combining assertions and suggestions or multiple suggestions:
class MakeGreeting4(dspy.Module):
def __init__(self, invalid_greetings = []):
self.invalid_greetings = invalid_greetings
self.prog = dspy.ChainOfThought("context -> greeting")
self.prev_greetings = []
def forward(self, context):
result = self.prog(context=context)
self.prev_greetings.append(result.greeting)
_greeting = result.greeting
print(_greeting)
greeting_violations = list(filter(lambda x: x.lower() in _greeting.lower(), self.invalid_greetings))
print(greeting_violations)
formatted = ", ".join(greeting_violations)
formatted_prev = ", ".join(self.prev_greetings)
dspy.Suggest(not bool(greeting_violations), f"Greetings like {formatted} are so bad, provide a different greeting.")
dspy.Suggest(not _greeting in self.prev_greetings, f"You've already used the greetings: {formatted_prev}, provide a different greeting.")
return resultIn this version, we’re using both dspy.Suggest twice to guide the model’s output. We don’t want “bad” greetings, and we also want to avoid repeating the same greeting.
mg4 = MakeGreeting4(invalid_greetings=['hello']).activate_assertions()
mg4.forward(context)ERROR:dspy.primitives.assertions:[2m2024-05-20T21:46:57.692787Z[0m [[31m[1merror [0m] [1mSuggestionFailed: Greetings like hello are so bad, provide a different greeting.[0m [[0m[1m[34mdspy.primitives.assertions[0m][0m [36mfilename[0m=[35massertions.py[0m [36mlineno[0m=[35m111[0m
ERROR:dspy.primitives.assertions:[2m2024-05-20T21:46:57.695313Z[0m [[31m[1merror [0m] [1mSuggestionFailed: You've already used the greetings: Hello!, Good morning!, provide a different greeting.[0m [[0m[1m[34mdspy.primitives.assertions[0m][0m [36mfilename[0m=[35massertions.py[0m [36mlineno[0m=[35m111[0m
ERROR:dspy.primitives.assertions:[2m2024-05-20T21:46:57.701223Z[0m [[31m[1merror [0m] [1mSuggestionFailed: You've already used the greetings: Hello!, Good morning!, Good afternoon!, provide a different greeting.[0m [[0m[1m[34mdspy.primitives.assertions[0m][0m [36mfilename[0m=[35massertions.py[0m [36mlineno[0m=[35m108[0m
Hello!
['hello']
Good morning!
[]
Good afternoon!
[]
Prediction(
greeting='Good afternoon!'
)Now when we run it again, you can see we get a different response.
mg4.forward(context)ERROR:dspy.primitives.assertions:[2m2024-05-20T21:46:58.915752Z[0m [[31m[1merror [0m] [1mSuggestionFailed: Greetings like hello are so bad, provide a different greeting.[0m [[0m[1m[34mdspy.primitives.assertions[0m][0m [36mfilename[0m=[35massertions.py[0m [36mlineno[0m=[35m111[0m
ERROR:dspy.primitives.assertions:[2m2024-05-20T21:46:58.917467Z[0m [[31m[1merror [0m] [1mSuggestionFailed: You've already used the greetings: Hello!, Good morning!, Good afternoon!, Hello!, Good morning!, provide a different greeting.[0m [[0m[1m[34mdspy.primitives.assertions[0m][0m [36mfilename[0m=[35massertions.py[0m [36mlineno[0m=[35m111[0m
ERROR:dspy.primitives.assertions:[2m2024-05-20T21:46:58.921285Z[0m [[31m[1merror [0m] [1mSuggestionFailed: You've already used the greetings: Hello!, Good morning!, Good afternoon!, Hello!, Good morning!, Good day!, provide a different greeting.[0m [[0m[1m[34mdspy.primitives.assertions[0m][0m [36mfilename[0m=[35massertions.py[0m [36mlineno[0m=[35m108[0m
Hello!
['hello']
Good morning!
[]
Good day!
[]
Prediction(
greeting='Good day!'
)This is just a glimpse of the power of using assertions and suggestions to guide the output of LLMs. As you continue to build and refine your own agent applications, I encourage you to explore these features further and find creative ways to leverage them to achieve your desired outcomes.
Configuring Assertions
One of the powerful features of DSPy’s assertions is the ability to customize their behavior to suit your specific needs. By default, the assertions we’ve seen so far will continue to backtrack and retry twice. However, you may want to adjust this behavior, such as limiting the number of retries allowed.
To do this, we can use Python’s partial function to create custom assertion handlers with different retry settings. For example, let’s create a version of our backtrack_handler that only allows a single retry:
from dspy.primitives.assertions import assert_transform_module, backtrack_handler
from functools import partial
one_retry = partial(backtrack_handler, max_backtracks=1)
g4_with_assert_1_retry = assert_transform_module(MakeGreeting4(), one_retry)Now, when we run the forward method on this modified module, it will only attempt to backtrack and retry the generation once before giving up.
g4_with_assert_1_retry.forward(context)You can experiment with different values for max_backtracks to find the right balance between output quality and performance for your specific use case.
Remember, each one of the backtracks costs you money - it’s all the original tokens and the updated instructions.
How do assertions work?
The way assertions work in DSPy is quite fascinating. When a constraint is not met, DSPy initiates an under-the-hood backtracking mechanism, offering the language model a chance to self-refine and proceed. This is achieved through a process called Dynamic Signature Modification.
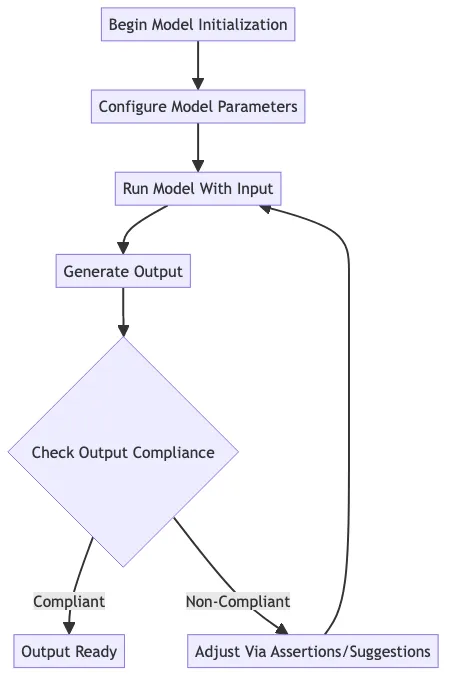
The conceptual flow is simple:
 {class=“xs:w-full w-1/2 mx-auto block border-2 border-gray-200 rounded-lg”}
{class=“xs:w-full w-1/2 mx-auto block border-2 border-gray-200 rounded-lg”}
Here’s how it works according to the docs
- Backtracking Mechanism: When the language model’s output fails to satisfy one or more of the assertions you’ve defined, DSPy triggers a backtracking process. This allows the model to revisit its previous output and try to generate a new response that meets the specified criteria.
- Dynamic Signature Modification: As part of the backtracking process, DSPy internally modifies the Signature of your DSPy program. It adds two new fields to the Signature:
Past Output: This field contains the model’s previous output that did not pass the validation.Instruction: This field provides the user-defined feedback message on what went wrong and what the model should try to fix.
Visually, you can think about the overall flow for our particular app (with user interaction) like this:
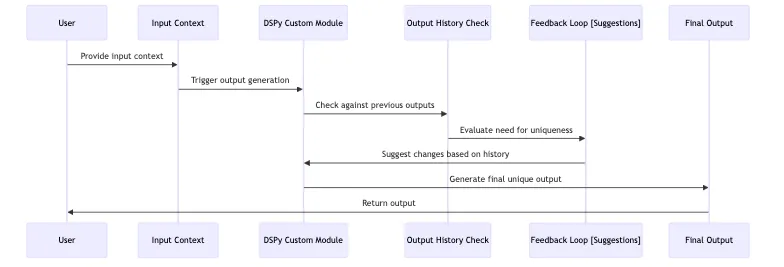 {class=“xs:w-full w-1/2 mx-auto block border-2 border-gray-200 rounded-lg”}
{class=“xs:w-full w-1/2 mx-auto block border-2 border-gray-200 rounded-lg”}
By adding these fields to the Signature, DSPy is essentially giving the language model more context and guidance on how to improve its output. The model can now see its previous response, understand where it fell short, and use the provided instructions to generate a new, more suitable output.
This dynamic modification of the Signature is a powerful feature of DSPy, as it allows the system to iteratively refine the model’s output until it meets the specified criteria. The language model can leverage the additional context and feedback to self-correct and produce a more desirable result.
The backtracking mechanism and dynamic Signature modification work together to create a feedback loop, where the model’s output is continuously evaluated, and the Signature is updated to provide more targeted guidance. This process continues until the maximum number of retries is reached.
Use Cases and Caveats
Now that we’ve explored the power of assertions and suggestions in guiding the output of our large language models, let’s take a look at some common use cases and potential caveats to keep in mind.
Use Cases for Assertions and Suggestions:
- Avoiding Certain Words or Phrases: Just like we saw in our example, you can use assertions to ensure that the generated output does not contain specific words or phrases that you deem undesirable. This can be particularly useful for maintaining a certain tone or avoiding potentially offensive language.
- Checking Output Structure: Assertions can also be used to validate the structure of the generated output, ensuring that it conforms to a specific format or contains the necessary components. This can be helpful for tasks like generating reports, summaries, or other structured responses.
- Conforming to Specific Criteria: Beyond just avoiding certain words or phrases, you can use assertions to enforce more complex criteria on the output. This could include things like ensuring the response is within a certain length, contains a minimum number of relevant facts, or adheres to specific style guidelines.
- Providing Contextual Guidance: Suggestions can be particularly useful for providing contextual guidance to the language model, such as reminding it of previous outputs or giving it additional instructions on how to improve the response.
While assertions and suggestions are powerful tools for guiding the output of large language models, it’s important to be mindful of a few caveats:
Performance Impact: Each time an assertion or suggestion is triggered, it results in an additional call to the language model. This can have a significant impact on the overall performance and latency of your application, especially if you’re using a large number of constraints or if the language model is slow to respond.
Balancing Guidance and Flexibility: It’s important to strike the right balance between providing enough guidance to the language model to ensure high-quality output, while still allowing it the flexibility to generate novel and creative responses. Too many assertions and suggestions can potentially stifle the model’s creativity and lead to overly formulaic or repetitive responses.
Mixing Assertions and Suggestions: While both assertions and suggestions can be powerful tools, it’s important to be mindful of how you use them together. Assertions that are too strict or suggestions that are too vague can lead to conflicting guidance and confusion for the language model.
As you explore the use of assertions and suggestions in your own projects, keep these caveats in mind and be prepared to experiment and iterate to find the right balance for your specific use case.
Conclusion and Next Steps
In this blog post, we’ve explored the powerful capabilities of DSPy’s assertions and suggestions, and how they can be used to guide the output of large language models (LLMs) to ensure quality, avoid hallucinations, and conform to specific requirements.
The key takeaways from our journey are:
-
Assertions: Assertions allow you to define strict requirements on the output of your LLM, ensuring that it meets certain criteria. We saw how to use assertions to prevent the generation of “bad” words or phrases, and how the backtracking mechanism in DSPy dynamically modifies the signature to provide feedback and guidance to the language model.
-
Suggestions: Suggestions offer a more flexible way to guide the LLM’s output, by providing alternative options or feedback when the output does not meet certain criteria. We explored how to use suggestions to avoid repeating previous outputs and to suggest alternative greetings.
For a deeper dive, check out the docs.
I hope this blog post has provided you with a solid foundation for understanding and leveraging the power of assertions and suggestions in your DSPy-based applications. As you continue to explore and experiment, feel free to reach out with any questions or feedback. I’m always excited to learn from the community and to see how different people are using these bleeding edge tools!