Building a RAG chatbot on a podcast using LlamaIndex, FAISS and OpenAI
Building a RAG Chatbot with LlamaIndex, FAISS, and OpenAI
What you’ll learn in this post
This post is going to teach you how to build a retrieval augmented generation (RAG) based chatbot on top of a podcast episode. We’re going to use several tools to do that:
- LlamaIndex - for orchestrating our data + LLMs
- Faiss - for similarity search
- OpenAI - as the LLM provider
- Unstructured.IO - for unstructured data processing
The end result is a pipeline that will allow us to chat with different latent.space podcasts.
Introducing the idea
There’s so much great information buried in podcasts.
The problem is that the ‘linear’ nature of podcasts makes it difficult to extract insights and get information quickly.
This post is going to teach you how to build a chatbot to do just that.
Now… there are a number of different paid / free tools to be able to do this. I’ve built one called sniplet.
These kinds of applications make for a GREAT project for learning that’s because they’re going to show us how to wire together…
- Simple data pipelines on unstructured data
- building chat and query models
- leveraging semantic search
The goal of this tutorial is to help you better understand how to build these kinds of tools. They are not magic. We’re just entering this wave of AI enabled applications that we, as developers, need to know how to build these things!
Let’s get right to it!
and what is RAG?
In a previous post, we built a RAG application from scratch. That tutorial used 0 libraries to walk through the key concepts of RAG.
For a formal definition, you should refer to the website and the paper but for our purposes.
The gist of the technique is to add your own data (via some retrieval tool) into the prompt that you pass into a large language model. With that, you get a result.
That gives you several benefits:
- You can include facts in the prompt to help the LLM avoid hallucinations
- You can (manually) refer to sources of truth when responding to a user query, helping to double check any potential issues.
- You can leverage data that the LLM might not have been trained on.
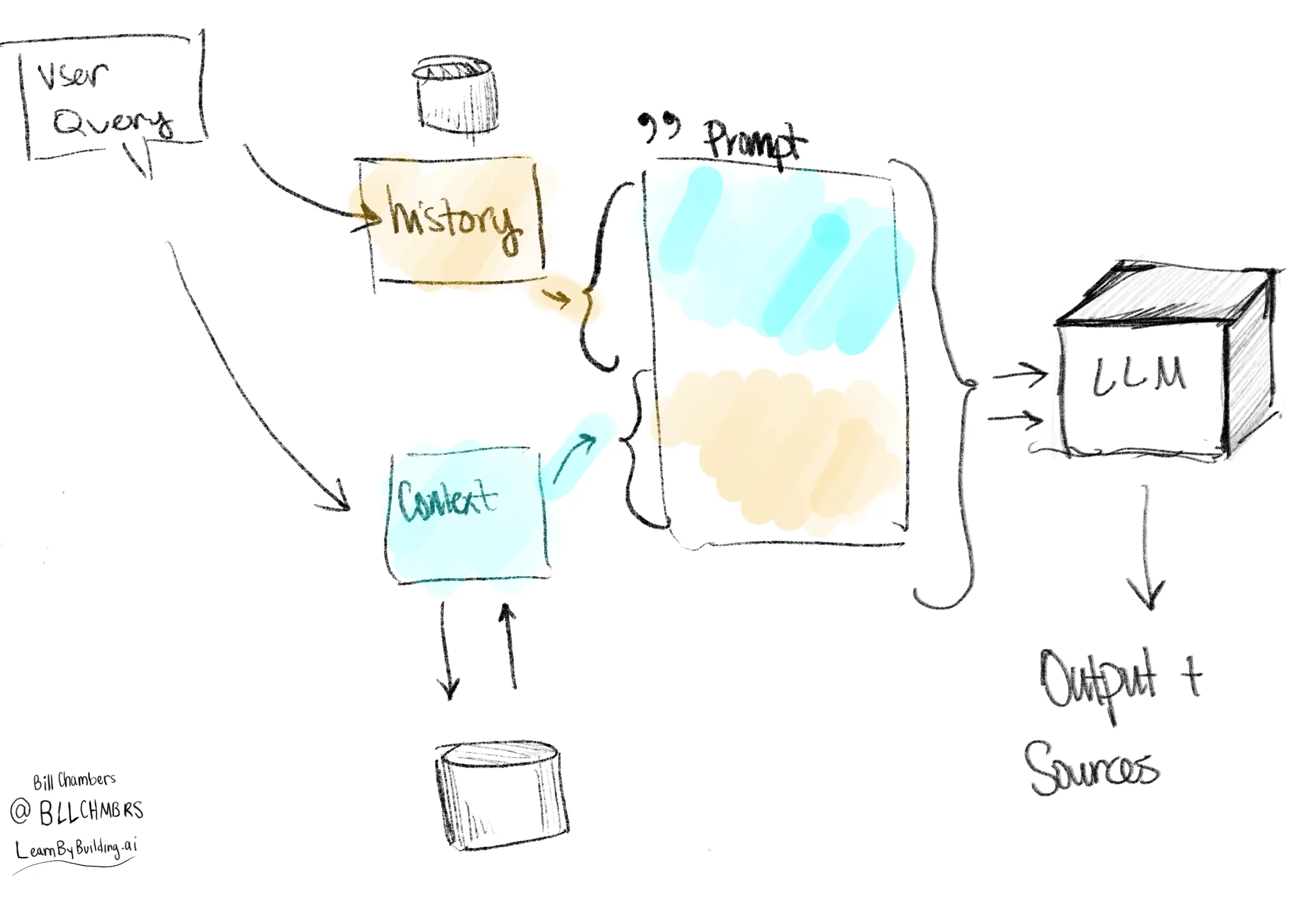
For the visual learners, here’s a simple diagram of a RAG query. We pull data from a database, combine that with the user query and other information into a prompt and pass that into the LLM.
The podcast we’ll be working with
We’ve got a podcast “RAG Is A Hack” with Jerry Liu (twitter, linkedin) on the Latent Space podcast.
What better way to explore RAG than by building a RAG-based chatbot on a podcast about RAG about a tool that provides tools for building RAG applications?
What’s nice about this podcast is that transcripts are INCLUDED. That means that it’s easy to access the written text of the podcast. In future episodes, we’ll explore getting transcripts for podcasts that don’t publish transcripts but doing so is beyond the scope of this particular tutorial.
Conceptually, what are the steps to build our application?
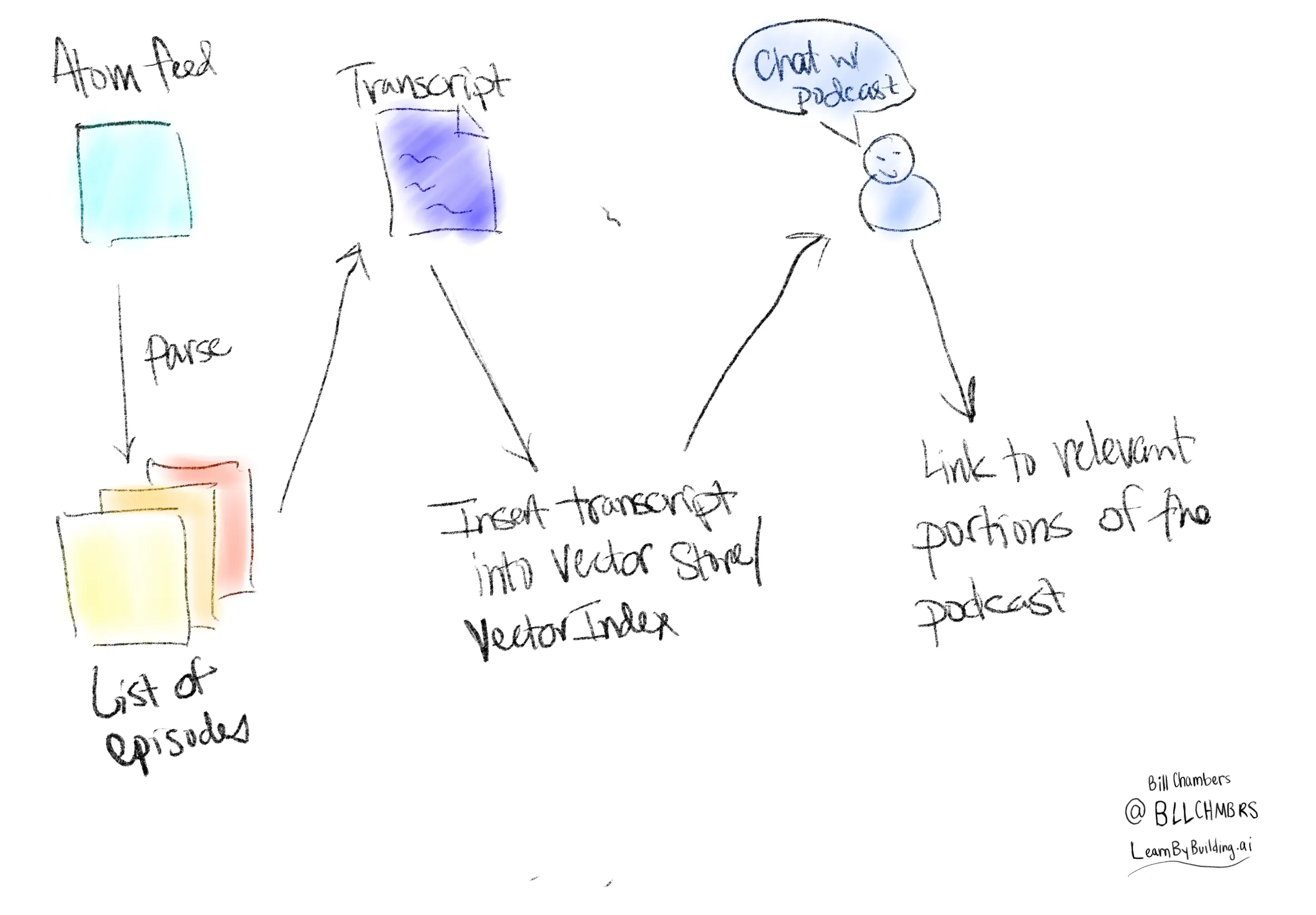
The steps are straightforward:
- Fetch the atom feed
- Parse that feed into something useful
- Look up a particular episode
- Get the (provided) transcript for that particular episode
- Index that particular transcript into a Vector Index for querying
- Perform Query based RAG on that input
Step 1, 2, and 3: Fetching & parsing the atom feed and episode
We’ll start off by grabbing the ATOM feed link of the podcast.
podcast_atom_link = "https://api.substack.com/feed/podcast/1084089.rss" # latent space podcastwe’ll use the feedparser library to parse the atom XML to something usable & structured.
import feedparserparsed = feedparser.parse(podcast_atom_link)
episode = [ep for ep in parsed.entries if ep['title'] == "RAG Is A Hack - with Jerry Liu from LlamaIndex"][0]episode_summary = episode['summary']
print(episode_summary[:100])<p><em>Want to help define </em><em>the AI Engineer stack</em><em>? >800 folks have weighed in on thSecurity Interlude: Now to make sure I don’t leak my OpenAI API key, I’m using a .env file. You can do the same!
from dotenv import load_dotenv
load_dotenv()TrueStep 4: Parse the summary into HTML and get the transcript
Every Latent Space podcast includes an HTML based summary and in that summary is the transcript.
To get at that summary, we’re going to have to parse that HTML. To do that, I’m going to use a library called unstructured. You can read more about it on the unstructured website but, in short, it provides a number of tools for parsing different kinds of data from PDFs to html. Basically ETL for LLMs.
For this, you might have to install another couple of dependencies.
brew install libxml2
brew install libxsltNow that that’s installed, it’s time to parse some HTML. We’re going to do that with the partition_html function.
from unstructured.partition.html import partition_html
parsed_summary = partition_html(text=''.join(episode_summary))Easy, simple, done.
Let’s look at the text and find where the transcript begins.
Most podcasts don’t have a free transcript available (which is in part by I built sniplet) but the latent.space podcast (generously) does.
I took a look at some episodes and the pattern is to begin the transcript with (🥁drumroll please🥁) Transcript.
start_of_transcript = [x.text for x in parsed_summary].index("Transcript") + 1
print(f"First line of the transcript: {start_of_transcript}")First line of the transcript: 75Introducing LlamaIndex
What is LlamaIndex?

LlamaIndex is a data framework for LLM applications to ingest, structure, and access private or domain-specific data.
LlamaIndex provides a number of nice tools when it comes to working with LLMs on your data.
- Data connectors (for connecting to your various data sources)
- Indexing capabilities (we’ll see one of those a bit later)
- and more!
The library provides a ton of vlaue to developers but this tutorial is going to start with the basics.
The first abstraction we’re going to use is one you’ll find in every RAG oriented library. A document abstraction.
LlamaIndex provides a document interface that allows us to convert our text into a Document object. We’ll add all the lines from the podcast into that object type to be able to query it.
from llama_index import Documentdocuments = [Document(text=t.text) for t in parsed_summary[start_of_transcript:]]Step 5: Build a VectorStoreIndex over that data
Now we’re going to be taking things to the next level and getting to the heart of the RAG system.
This is going to involve a couple of substeps:
- Choose / Leverage a vector store
- Embed our data
- Query the resulting index to ask questions of the podcast
We’re going to operate very simply and use Facebook AI Similarity Search referred to as Faiss. Now Faiss can run on a bunch of different hardware, but for our purposes we are going to install the CPU version. Checkout the github for installation instructions.
Faiss allows for you to search our text data effectively.
FAISS (Facebook AI Similarity Search) is a library that allows developers to quickly search for embeddings of multimedia documents that are similar to each other. It solves limitations of traditional query search engines that are optimized for hash-based searches, and provides more scalable similarity search functions.
The Faiss wiki has a great primer on similarity search.
Hold up, what the &*#@$ are embeddings and hash-based searches?
Alright, let’s take a pause to explain the basics. As you (hopefully) read in our Building a RAG Application from Scratch post, we’re going to want to do more than just search based on keywords in the transcripts. What we want to do, and what makes generative AI so exciting in some sense, is the fact that we can search by semantics.
Hold up, what are semantics?
Semantics are the meaning of a word, as opposed to just the collection of characters that we see on a screen on paper.
A simple example:
- “It’s cold outside”
- “He was cold to me”
Cold in both of these sentences is the same word. But semantically it’s different. In the first it describes temperature, in the second it describes a feeling. There are different definitions and semantics for “cold”. Common keyword (hash-based) search wouldn’t understand that but semantic search does.
Back to the topic: embeddings
Now that we’ve understood semantics, we can get to embeddings. Embeddings are, in simplest terms, an easy way to convert words into numbers. The numbers that we convert text into represent a vector. The distiance between two vectors represents their similarity (small distance) or difference (large distance).
We’re going to use an embedding provided by OpenAI for this tutorial but there is a MASSIVE world of embeddings and this is an active area of research that has legs.
As an aside, we could just as well use a product like Pinecone or Weaviate but for now. Recommendations for each one is outside of the scope of this tutorial.
With some background covered, we can continue. Let’s create our faiss index.
import faiss
d = 1536 # dimensions of text-ada-embedding-002, the embedding model that we're going to use
faiss_index = faiss.IndexFlatL2(d)Specifying the embedding model and query model
Now we’re going to use two different LLMs. We’re going to use the OpenAIEmbedding as well as an OpenAI model.
from llama_index.llms import OpenAI
from llama_index.embeddings import OpenAIEmbedding
embed_model = OpenAIEmbedding()
llm = OpenAI(model="gpt-4")Now that we’ve done that, we need to tell the application to use them. In LlamaIndex, you do that with a ServiceContext.
from llama_index import ServiceContext, set_global_service_context
service_context = ServiceContext.from_defaults(llm=llm, embed_model=embed_model)
set_global_service_context(service_context)Embedding and querying the data
Now that we’ve created our index, we now need to be able to put data into that index.
But what about costs?
So far, we’ve spent 0 dollars. But embedding costs money (unless you’re using an open source model on your local machine) as well as an LLM. Since we’re using OpenAI. we can calculate our costs ahead of time (or at least an estimate), using the code below. This won’t be exact but tiktoken will tell us how much it costs to embed or pass all the tokens into the model or the embedding.
import tiktoken
e = tiktoken.encoding_for_model("gpt-4")
total_tokens = sum([len(e.encode(x.text)) for x in parsed_summary[start_of_transcript:]])
total_tokens * 0.03 / 1000 # total cost to put into a prompt of GPT, ~60 cents
total_tokens * 0.0001 / 1000 # total cost to embed, .002 cents0.0021967from llama_index import StorageContextPerforming the embedding
Now we can instantiate the VectorStoreIndex.
Now we’ll go ahead and instantiate the vector store and index. Note that just as we defined a ServiceContext, we’re now going to show a StorageContext which specifies where to store documents, indexes, vectors and more.
You’ll see that we specify show_progress=True to watch the embedding take place. This should only take a 10 seconds or so.
from llama_index import VectorStoreIndex, StorageContext
from llama_index.vector_stores.faiss import FaissVectorStore
vector_store = FaissVectorStore(faiss_index=faiss_index)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(documents, storage_context=storage_context, show_progress=True)/Users/williamchambers/miniconda3/envs/lbb/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Parsing documents into nodes: 100%|█|
Generating embeddings: 100%|█| 300/300Now we’re ready to query the index!
Step 6: Querying Data
Now we can get to querying! Let’s take a look at what Jerry thinks about RAG!
query = "What does Jerry think about RAG?"
response = index.as_query_engine(similarity_top_k=3).query(query)response.response"Jerry believes that RAG increases transparency and visibility into documents. He also thinks that in the long term, fine tuning might memorize some high-level concepts of knowledge, and RAG will supplement aspects that it doesn't know. He suggests that improvements to RAG could involve aspects like chunking and metadata."The response makes a lot of sense, but where things get interesting are the references.
Remember above when we talked about semantics search? Well what’s happening under the hood is that the Faiss library is computing the similarities between our query and the hundreds of lines of text from the transcript. It finds the “chunks” that are most similar to our query. The “chunking” is a huge area of opportunity for optimization (and we’ll spend a lot of time on this in later posts) but for now, we’re just working with the defaults.
Right now, we’re each item of output by the unstructured library as an individual document. This isn’t exactly correct, but it’s sufficient for us to get a gentle introduction. We’ll get to that as a follow up a bit later.
Here are the “documents” and the similarity scores:
for node in response.source_nodes:
print(f"{node.get_score()} 👉 {node.text}")0.24235212802886963 👉 Jerry: So, so I think what RAG does is it increases like transparency, visibility into the actual documents, right. [00:26:19]
0.250153124332428 👉 Jerry: I mean, I think in the longterm, like if like, this is kind of how fine tuning, like RAG evolves. Like I do think there'll be some aspect where fine tuning will probably memorize some high level concepts of knowledge, but then like RAG will just be there to supplement like aspects of that, that aren't work that don't, that, that it doesn't know.
0.28081560134887695 👉 Jerry: To improve rag, like everything that we talked about, like chunking, like metadata, like. [00:57:24]Couple of things to note here:
- This is a pretty good summary of his perspective.
- The referenced ‘documents’ are quite short. Just a sentence or two.
What about just including more results and see if we get a better answer?
query = "What does Jerry think about RAG?"
response = index.as_query_engine(similarity_top_k=10).query(query)print(response.response)Jerry believes that RAG increases transparency and visibility into documents. He sees it as a tool that can supplement high-level concepts of knowledge that fine-tuning might not cover. He also mentions that RAG is currently the default way to augment knowledge. Jerry appreciates the algorithmic aspect of RAG, viewing it as a good hack that involves figuring out algorithms to retrieve the right information and stuff it into the prompt of a language model. He also sees RAG as advantageous because it allows for access control with an external storage system, something that large language models can't do. Furthermore, Jerry thinks that RAG is easier to onboard and use, making it a more accessible choice for most people compared to fine-tuning.This answer is a bit more more nuanced because we’re including more context to the model about what Jerry said throughout the podcast.
We can see now that we’re going to have more sources as well.
print(len(response.source_nodes))10This gets at something that we can tune quite a bit to evaluate how our RAG pipeline is performing.
We can do things like…
- specify a similarity threshold (e.g., everything below 0.3)
- We could make chunks a bit larger
- We could include surrounding chunks
The sky is really the limit here. What’s awesome about LlamaIndex is that it can take on a lot of this heavy lifting for us.
Querying the data with chat and memory
Now we’ve built this query interface, but that won’t include is the history of our conversation. We can’t ask follow up questions and get more information.
For that, we need to include a different chat_mode which specifies the behavior of the chat application. Here are the currently available chat modes (as of the time of this writing):
best- Turn the query engine into a tool, for use with a ReAct data agent or an OpenAI data agent, depending on what your LLM supports. OpenAI data agents require gpt-3.5-turbo or gpt-4 as they use the function calling API from OpenAI.context- Retrieve nodes from the index using every user message. The retrieved text is inserted into the system prompt, so that the chat engine can either respond naturally or use the context from the query engine.condense_question- Look at the chat history and re-write the user message to be a query for the index. Return the response after reading the response from the query engine.simple- A simple chat with the LLM directly, no query engine involved.react- Same as best, but forces a ReAct data agent.openai- Same as best, but forces an OpenAI data agent.
We’ll go into different chat agents in a different post. Let’s get back to querying.
query = "What does Jerry think about RAG?"
chat_eng = index.as_chat_engine(similarity_top_k=10, chat_mode='context')
response = chat_eng.chat(query)print(response.response)Jerry believes that RAG (Retrieval-Augmented Generation) is a useful tool for increasing transparency and visibility into documents. He sees it as a way to supplement the knowledge that a fine-tuned model might not have. He also mentions that RAG is currently the default way to augment knowledge. Jerry appreciates the simplicity of RAG, describing it as a good hack that involves stuffing information into the prompt of a language model. He also sees RAG as advantageous for access control, something that can't be done with large language models. He believes that RAG is easier to use and onboard, making it a more practical choice for most people compared to fine-tuning. However, he also acknowledges that fine-tuning could potentially take over some aspects of what RAG does in the future.print(len(response.source_nodes))10what makes chat different than query?
With chat, we can ask follow up questions because the tool will store memory over time on our behalf. Storing memory is simpl;e, it just means saving previous questions and answers.
chat_eng.chat_history[ChatMessage(role=<MessageRole.USER: 'user'>, content='What does Jerry think about RAG?', additional_kwargs={}),
ChatMessage(role=<MessageRole.ASSISTANT: 'assistant'>, content="Jerry believes that RAG (Retrieval-Augmented Generation) is a valuable tool for increasing transparency and visibility into documents. He sees it as a way to supplement the knowledge that a fine-tuned model may not have. He also mentions that RAG can be improved through methods like chunking and metadata. \n\nJerry views RAG as the default way to augment knowledge and appreciates the ability to control access with RAG, which is not possible with large language models. He also sees RAG as a good hack, as it allows for the optimization of a system's weights to achieve a specific function. \n\nHe believes that RAG is easier to onboard and use compared to fine-tuning, making it a more accessible choice for most people. However, he also acknowledges that fine-tuning could potentially take over some aspects of what RAG does in the future.", additional_kwargs={})]Here you can see that with that follow up question, it retains the context we have so far.
query_2 = "How does he think that it will evolve over time?"
response_2 = chat_eng.chat(query_2)print(response_2.response)Jerry believes that there will be an increasing interplay between fine-tuning and RAG as time goes on. He thinks that fine-tuning will probably memorize some high-level concepts of knowledge, while RAG will be there to supplement aspects that it doesn't know. He also suggests that there might be some aspect of personalization of memory in the future, where a personalized assistant can learn behaviors over time and learn through conversation history. He believes that this will be part of the ongoing continuous fine-tuning.In production, we’ll want to save the chat history so that we can tune and debug our model over time but for now we can just look at this particular memory.
Memory (or rather, how we store and compress it) is another thing we can tune and there’s a lot of discussion about “memory” in industry.
If you think about it, storing information in a semantic database (e.g., the retrieval part of RAG), is a kind of “memory”.
The model itself has its own “memory” from all the data that it’s seen.
In fact, the authors of the RAG paper called this out explicitly in their blog post:
RAG’s true strength lies in its flexibility. Changing what a pretrained language model knows entails retraining the entire model with new documents. With RAG, we control what it knows simply by swapping out the documents it uses for knowledge retrieval.
Memory and concepts of memory will evolve over the coming years, but for now what seems most practical is storing facts and references in a semantic database and letting the model / managed conversation memory handle the rest.
So what’s happening under the hood?
Alright, so we’ve built this application, let’s talk about what’s going on under the hood.
The API we’re using above is the “high level” API. It’s intended to simplify the base use cases. In more detail, the flow we see when querying the model is:
- the
chat_enginereceives a message - It gets the context that it wants to give to the model (e.g., the sources). It includes those with a prompt (we’ve just used the basic prompt at this point).
- It gets the history of the conversation
- It passes all of that into the LLM
In short, llamaindex adds the message to the memory, fetches the context (from the database / retriever), then passes all of that into the LLM. Now all if this can be customized. We’ll cover that information in later topics.
🚨🚨🚨 Advanced readers only🚨🚨🚨 For those that want to dive super deep, take a look at the
chat_enginecode. The code is quite neat, so it’s not hard to understand. One word of caution, don’t depend on internal names in production (or even development). The LlamaIndex authors are deliberate about what’s in public and what’s in private. However, this will give you a better understanding of what exactly is happening under the hood.
so, why is RAG a hack?
The podcast title, the discussion. RAG is a hack, let’s talk about why that is.
At its core, RAG involves stuffing the right information into the prompt. It’s no different from “prompt engineering” that you might be doing on your local machine - it just does that with an automated database lookup.
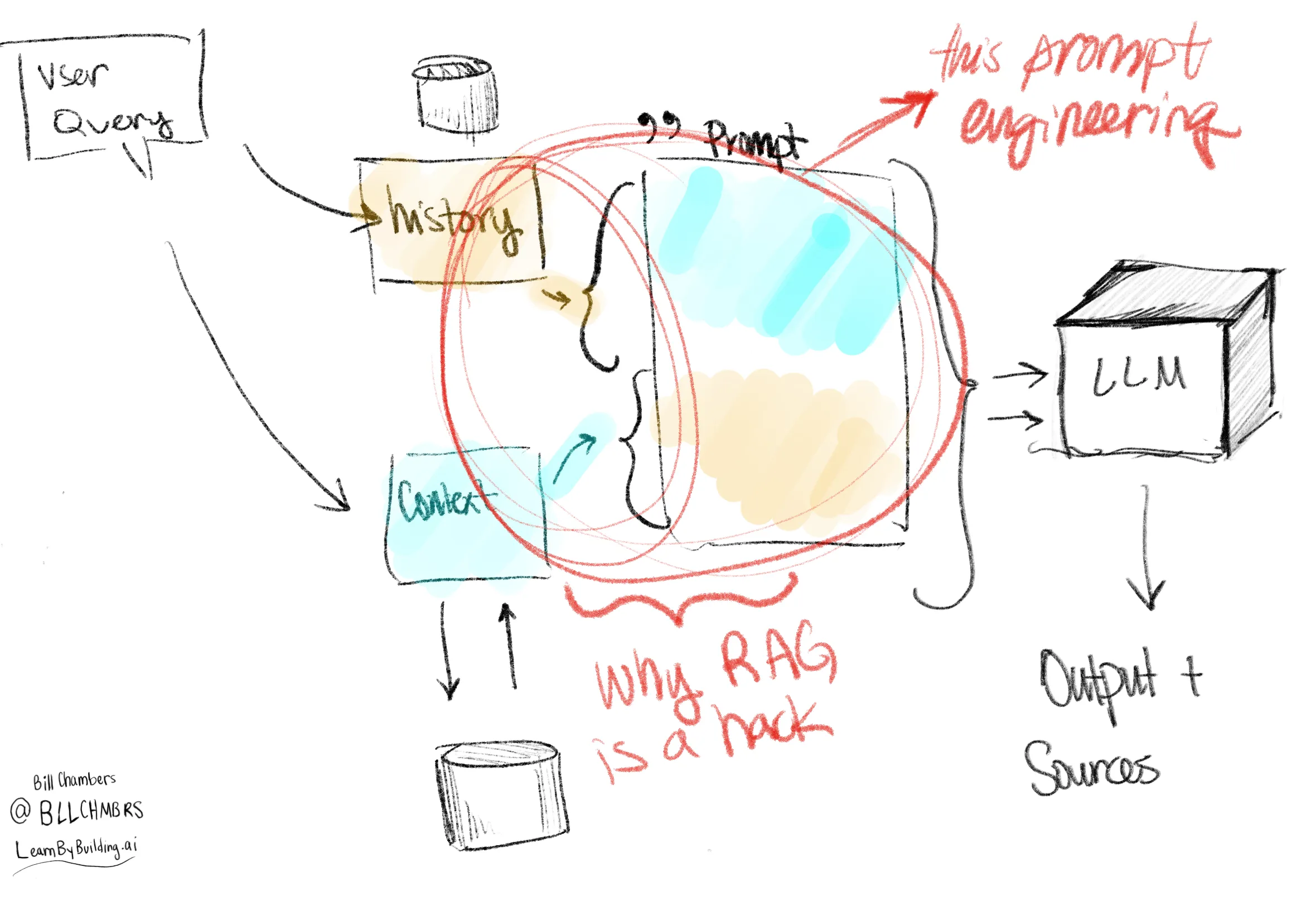
That makes it “inelegant” because it’s just forcing the right stuff into the prompt to get better answers. That makes it very practical and effective, but not necessarily perfect and not necessarily the most “clean” solution either.
But if it works, it works and that’s why it has so much excitement.
Final thoughts
We’ve learned a ton in this post about building RAG applications, from basic querying to chatbots. As we discussed in our previous post, there’s much to tune. In later posts, we’ll discuss the details of how we can go about customizing our prompts, tuning the chunk sizes for our context and so much more!
This post was originally published on LearnByBuilding.AI. See the notebook and code on Github. Please reach out to me on twitter with any questions or feedback!