Building a Retrieval Augmented Generation (RAG) system from scratch - Part 2: Semantics
A beginner’s guide to building a RAG application from scratch part 2 - Semantic Search
In our last post on building RAG from scratch. We explored the fundamentals of building a RAG application.
We covered the fundamentals of a RAG system:
- a collection of documents (formally called a corpus)
- An input from the user
- a similarity measure between the collection of documents and the user input
And then we built that using Jaccard Similarity (a very, very basic measure of similarity.)
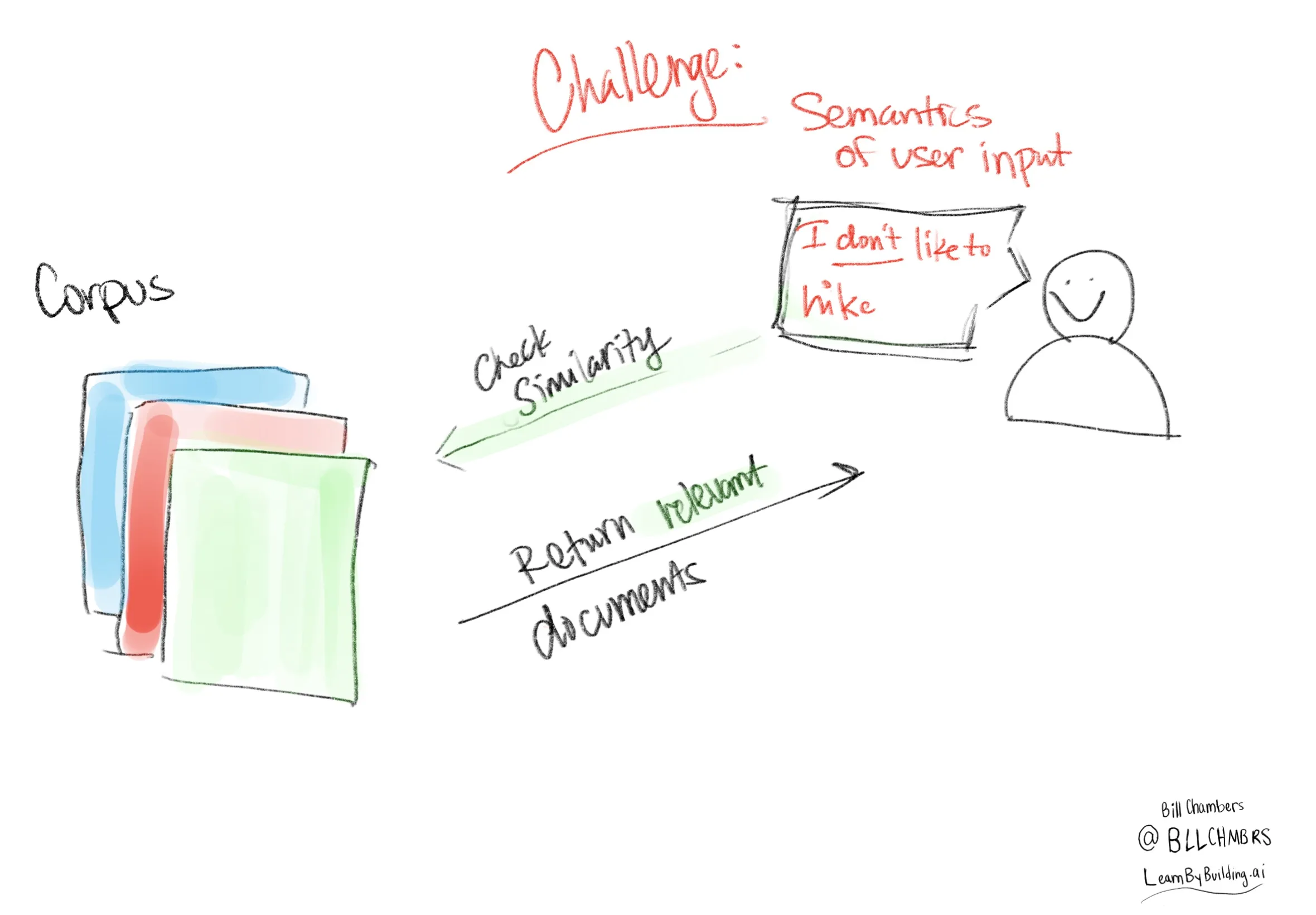
The challenge is, that we can do better. Jaccard Similarity is a simple measure that only looks at the overlap of words between the user input and the documents. It doesn’t take into account the meaning of the words or the context in which they are used.
Those are what we can semantics. Let’s work through exactly what that means and how we can use it to improve our RAG system. We’re primarily going to focus on #3 that we defined above, the similarity measure.
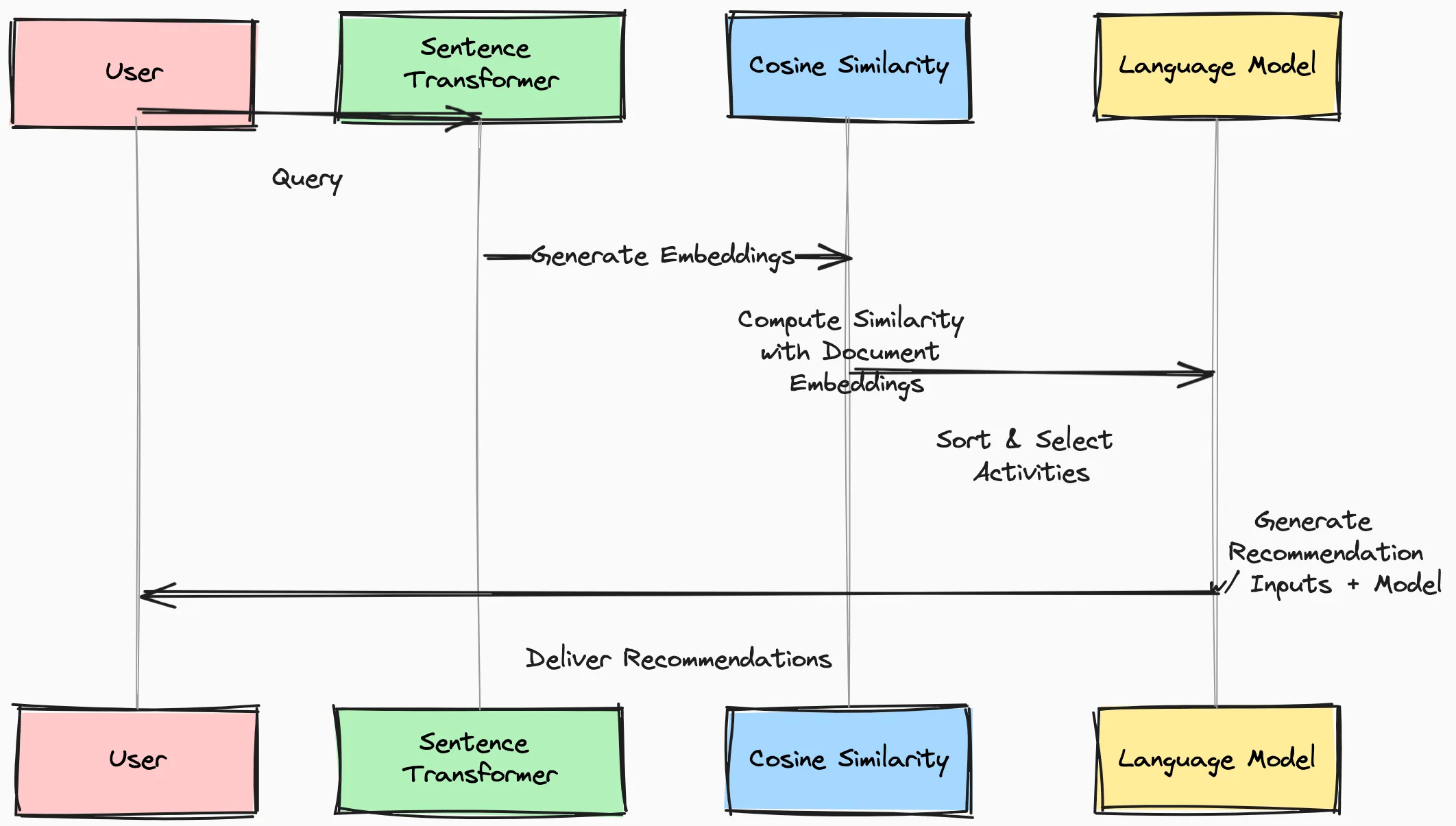
Here’s the sequence diagram of what we’ll be covering:
But how do you get semantics?
We discussed that our current measures of similarity are just too simple. So how can we take that to the next level?
We’re going to do that with Sentence Transformers, a python library for basically turning text into numbers.
Getting started with Sentence Transformers
In our previous post, we didn’t introduce embeddings. Let’s do that before we get started with sentence transformers.
Embeddings are a way of converting one representation to another. Text is a representation. Integers are a representation, floats are another. Embeddings create sequences of numbers that represent the text that we input.
These embeddings capture the semantic meaning of the input text, allowing us to measure the similarity between different pieces of text.
For instance, we can see that the sentences: “Take the leisurely walk in the woods” and “Enjoy a stroll outside” convey similar meanings.
This also shows us the limits of Jaccard Similarity. These two sentences have no overlapping words. But they mean almost the same thing. They would have a terrible Jaccard similarity score.
They have no overlapping words! But they mean almost the same thing.
By encoding these sentences into embeddings, we can compare them based on their semantic similarity rather than just their word overlap.
We’ll use the all-MiniLM-L6-v2 model. It’s compact and efficient version of the original Transformer-based model (h/t chatgpt). Importantly, you can run it on your laptop easily.
Semantics
The embeddings generated by the embedding model represent the input text in a high-dimensional vector space. That’s really just a wordy way of saying “similar text is closer together.”
This means that words, phrases, and sentences that convey similar meanings will have embeddings that are more similar to each other. We measure this similarity using a similarity measure, in this case, cosine similarity.
This gives us the ability to capture the underlying meaning (semantics!) of the user’s input and the documents in our corpus. This allows us to move beyond simple keyword matching.
In the next section, we’ll pick off where we left off in our previous tutorial.
Gathering our documents
The corpus of documents used in this example is a collection of 10 short descriptions of various leisure activities (same as part 1).
corpus_of_documents = [
"Take a leisurely walk in the park and enjoy the fresh air.",
"Visit a local museum and discover something new.",
"Attend a live music concert and feel the rhythm.",
"Go for a hike and admire the natural scenery.",
"Have a picnic with friends and share some laughs.",
"Explore a new cuisine by dining at an ethnic restaurant.",
"Take a yoga class and stretch your body and mind.",
"Join a local sports league and enjoy some friendly competition.",
"Attend a workshop or lecture on a topic you're interested in.",
"Visit an amusement park and ride the roller coasters."
]Calculating similarity
Here are the steps we’ll talk to calculate similarity:
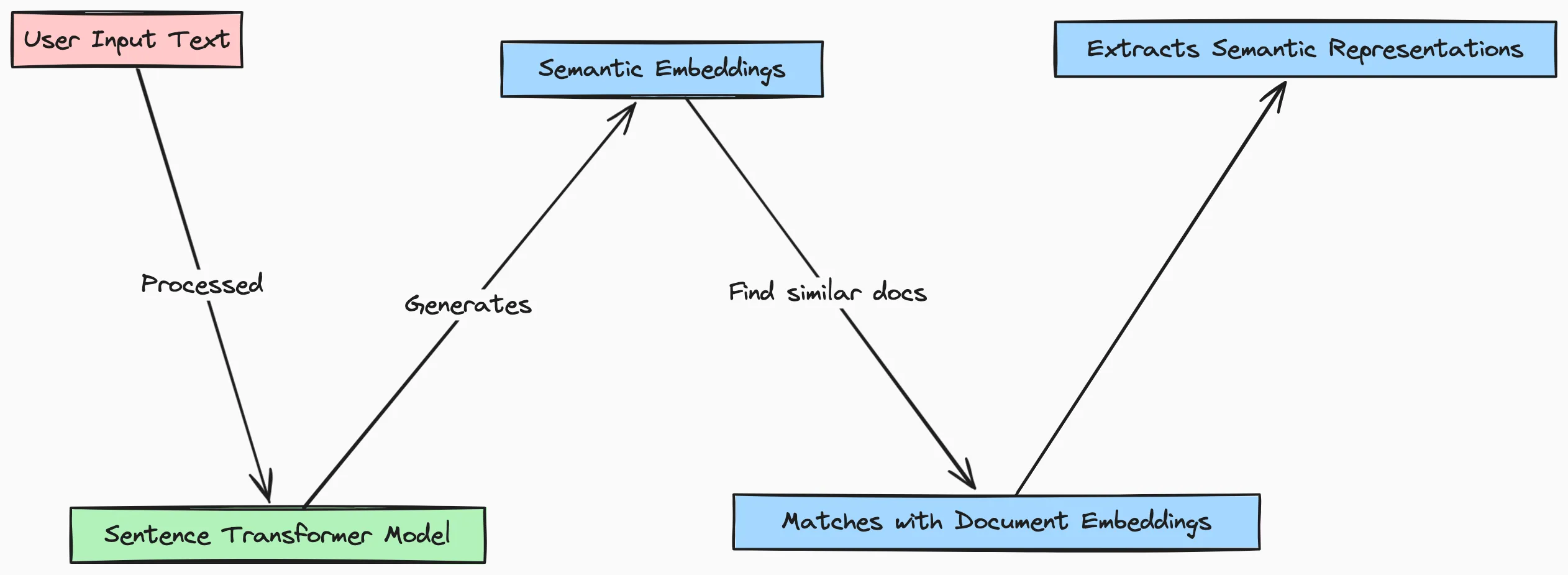
Encoding
First, we’ll use the Sentence Transformer model to encode the entire corpus of documents into a set of embeddings:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
doc_embeddings = model.encode(corpus_of_documents)The SentenceTransformer model takes the list of documents corpus_of_documents as input and returns a matrix of document embeddings, where each row represents the vector encoding of the corresponding document.
Here’s what our document embeddings look like:
array([[ 0.07121077, -0.01088003, 0.11746485, ..., 0.01414924,
-0.13175762, -0.00402598],
[ 0.04881528, -0.03166641, 0.07468717, ..., -0.0627827 ,
-0.11120284, 0.03045147],
[ 0.05019967, -0.09127751, 0.08517756, ..., 0.01286453,
-0.07415231, -0.06140357],
...,
[ 0.05416266, -0.03030902, 0.02475943, ..., -0.01272294,
-0.06512289, 0.05848261],
[-0.00401894, -0.04562395, -0.00900753, ..., 0.03939738,
-0.12731643, 0.05255723],
[ 0.0504604 , 0.0143044 , 0.08787955, ..., -0.01778724,
-0.05246406, -0.02887336]], dtype=float32)Computing
Remember, we need a measure of similarity. While there are several, a popular and common one is cosine similarity.
With the document embeddings in hand, we can now calculate the semantic similarity between the user’s query and each document in the corpus. We’ll use the cosine similarity metric, which measures the cosine of the angle between two vectors:
from sklearn.metrics.pairwise import cosine_similarity
query = "What's the best outside activity?"
query_embedding = model.encode([query])
similarities = cosine_similarity(query_embedding, doc_embeddings)The cosine_similarity() function from scikit-learn takes the query embedding and the document embeddings as input, and returns a vector of similarity scores. Each score represents the semantic similarity between the query and the corresponding document.
When we calculate similarities, here’s what we see:
array([0.502352 , 0.32826388, 0.31544408, 0.50193346, 0.44371974,
0.18485212, 0.21045846, 0.25540656, 0.2216403 , 0.45777753],
dtype=float32)Ranking and Recommending Activities
After calculating the semantic similarity between the user’s query and the documents in the corpus, the next step is to rank the documents and select the most relevant ones to recommend to the user.
Sorting Similarity Scores
The first step is to sort the similarity scores in descending order. This will allow us to identify the documents that are most semantically similar to the user’s query.
indexed = list(enumerate(similarities[0]))
sorted_index = sorted(indexed, key=lambda x: x[1], reverse=True)In the code above, we first create a list of tuples, where each tuple contains the index of the document and its corresponding similarity score. We then sort this list in descending order based on the similarity scores.
Selecting Top-Ranked Documents
Once the similarity scores are sorted, we can select the top-ranked documents to recommend to the user. To do this, we can apply a similarity threshold to filter out the less relevant documents.
recommended_documents = []
for value, score in sorted_index:
formatted_score = "{:.2f}".format(score)
print(f"{formatted_score} => {corpus_of_documents[value]}")
if score > 0.3:
recommended_documents.append(corpus_of_documents[value])Here are the results:
0.50 => Take a leisurely walk in the park and enjoy the fresh air.
0.50 => Go for a hike and admire the natural scenery.
0.46 => Visit an amusement park and ride the roller coasters.
0.44 => Have a picnic with friends and share some laughs.
0.33 => Visit a local museum and discover something new.
0.32 => Attend a live music concert and feel the rhythm.
0.26 => Join a local sports league and enjoy some friendly competition.
0.22 => Attend a workshop or lecture on a topic you're interested in.
0.21 => Take a yoga class and stretch your body and mind.
0.18 => Explore a new cuisine by dining at an ethnic restaurant.In this example, we iterate through the sorted list of document-score pairs. We print the similarity score and the corresponding document for each pair. We then check if the similarity score is greater than 0.3 (the threshold), and if so, we add the document to the recommended_documents list.
The choice of the similarity threshold is an important consideration, as it determines the balance between precision and recall in the recommendations. A higher threshold will result in fewer, but more relevant, recommendations, while a lower threshold will provide more recommendations, but with potentially lower relevance.
By ranking the documents based on their semantic similarity to the user’s query and applying a similarity threshold, the RAG system can effectively identify and recommend the most relevant activities to the user.
Integrating with a Language Model for Natural Responses
To enhance the quality and coherence of the recommendations, we will integrate a pre-trained language model, such as Llama, into our activity recommendation system. By combining the power of semantic similarity and language modeling, we can generate more natural and personalized responses for the user.
The Prompt Engineering Process
The key to effectively leveraging the language model is through prompt engineering. We will create a prompt template that combines the user’s input and the recommended activity from the previous step. This template will serve as the input to the language model, which will then generate a coherent and natural-sounding recommendation.
The prompt template might look something like this:
prompt = """
You are a bot that makes recommendations for activities. You answer in very short sentences and do not include extra information.
These are potential activities:
{recommended_activities}
The user's query is: {user_input}
Provide the user with 2 recommended activities based on their query.
"""
recommended_activities = "\n".join(recommended_documents)In this template, the {recommended_activities} and {user_input} placeholders will be filled with the relevant information from the previous steps.
Generating the Final Recommendation
Now we’ll run the whole thing. Once the prompt is prepared, we can send it to the language model and retrieve the generated response. The language model will take the prompt as input and generate a concise and natural-sounding recommendation that combines the user’s preferences and the selected activities.
user_input = "I like to hike"
full_prompt = prompt.format(user_input=user_input, recommended_activities=recommended_activities)Then run model execution:
url = 'http://localhost:11434/api/generate'
data = {
"model": "llama2",
"prompt": full_prompt
}
headers = {'Content-Type': 'application/json'}
response = requests.post(url, data=json.dumps(data), headers=headers, stream=True)
full_response=[]
try:
count = 0
for line in response.iter_lines():
#filter out keep-alive new lines
# count += 1
# if count % 5== 0:
# print(decoded_line['response']) # print every fifth token
if line:
decoded_line = json.loads(line.decode('utf-8'))
full_response.append(decoded_line['response'])
finally:
response.close()
print(''.join(full_response)) Sure, here are two recommended activities for someone who likes to hike:
1. Go for a hike and admire the natural scenery.
2. Visit an amusement park and ride the roller coasters.Boom. We’ve got our recommendations.
Large language models give us the ability to take the information that we looked up and generate a response that is coherent and natural. This is the goal of any RAG system.
- Gather relevant context from a bunch of documents that we already have.
- Synthesize that information into a response that is coherent for the end user.
What will you do next?
In this guide, we’ve built a Retrieval Augmented Generation (RAG) system that can provide personalized recommendations for leisure activities based on user input.
We did this from scratch. In part 1 of the series, we did it with Jaccard Similarity. In this post, we took things to the next level by integrating cosine similarity and semantics. While that sounds more complicated, it’s really the same - all we did was upgrade our search function.
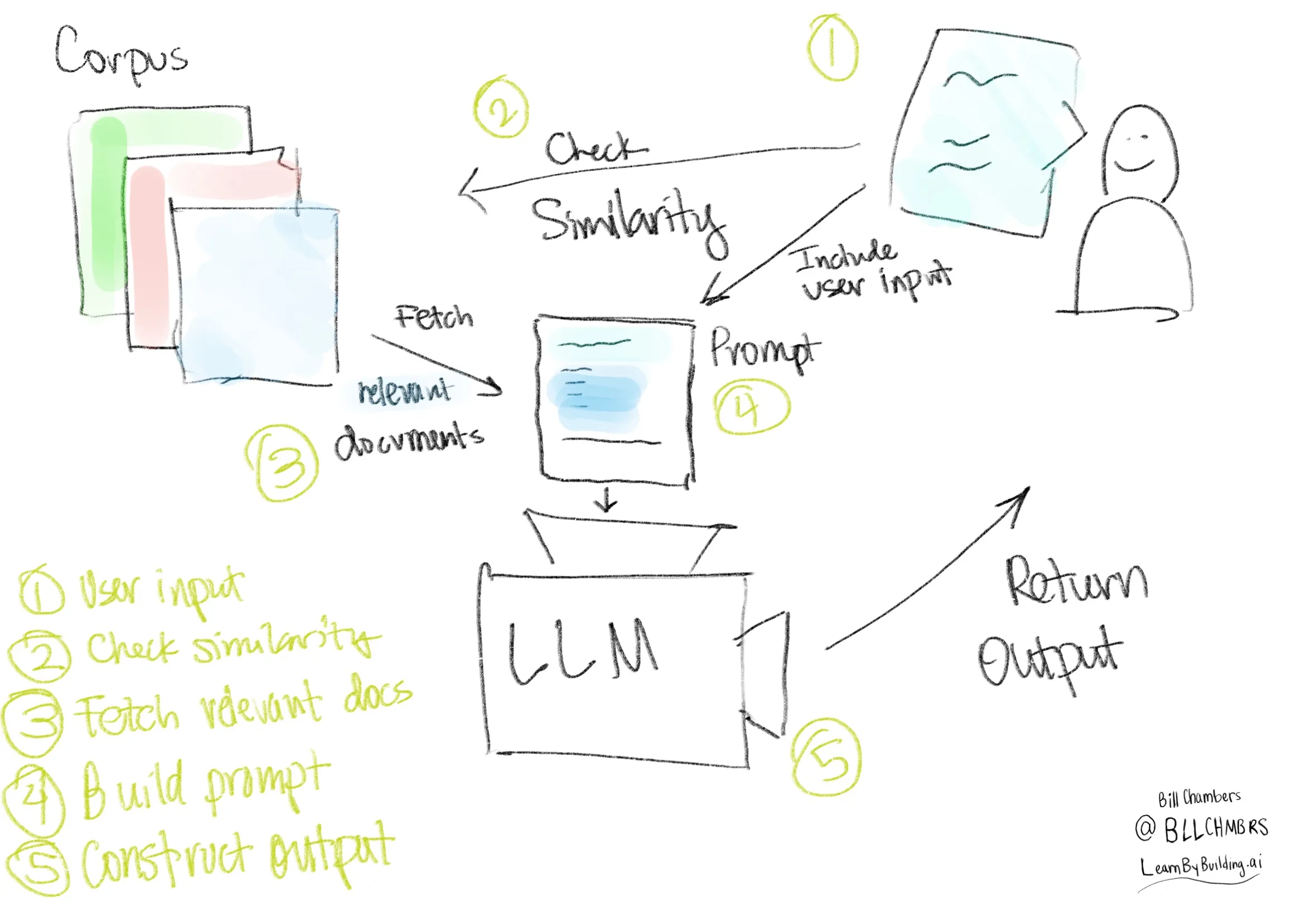
Visually, we can return to our RAG sequence diagram:
Not too different from our original diagram, just with a few more steps.
Drop a comment or ping me on twitter if you found this useful! I’d love to hear what you’re building with RAG!