Uncovering the Best LLM Data Extraction Library - Instructor vs. Marvin vs. Guardrails

Uncovering the Best LLM Data Extraction Library: Instructor vs. Marvin vs. Guardrails
The AI world has been set ablaze with the capabilities of generative models, with their ability to weave together narratives and emulate human-like text generation. However, beneath this generative surface lies another profound capability: structured data extraction.
Data extraction is a far more common use case (today) than generation, in particular for businesses. Businesses have to process all kinds of documents, exchange them and so on. Businesses have to process all kinds of documents, exchange them, and LLMs provide a simple way of approaching this problem.
This post is going to show you 3 key things:
- how to think about data extraction with LLMs and
- how several libraries approach that problem
- which library is best for you between Instructor, Marvin, and Guardrails AI
Let’s get started!
Background - why is this important?
Let’s cover some basic background:
- Natural information (like text or audio) has valuable information. But working with this information is notoriously challenging. For instance, you might need a team of NLP researchers or ML engineers to be able to extract valuable information. This might be cost prohibitive to even start building certain kinds of applications.
- Large language models have shown a unique ability to generate unstructured text. What’s a more novel idea is the ability to generate structured data from unstructured data.
The key idea is: leverage the power of large language models to not just generate information but also parse information into structured data that we can use for other applications.
For instance, you might want to parse PDFs into structured data that you can use for other applications.
One reason why this is so interesting is that for business, this is a huge use case. There are a massive amount of unstructured => structured data extraction use cases and these tools could end up making a huge difference in how much that use case can actually be applied.
This isn’t exciting as creating images of kittens and dogs with Dall-E 3, but it’s close.

What’s the necessary technical background to understand about structured data extraction and LLMs?
Function Calling
The foundation of this is the OpenAI Function Calling API. This API allows you to call functions on LLMs and get back structured data. This is the foundation of all of the libraries that we’re going to discuss.
The problem with the function calling capability is that building these kinds of functions is a bit… tedious and requires serious boilerplate. For instance, for this function
def get_current_weather(location, unit="fahrenheit"):
"""Get the current weather in a given location"""
weather_info = {
"location": location,
"temperature": "72",
"unit": unit,
"forecast": ["sunny", "windy"],
}
return json.dumps(weather_info)You’ve got to write the following:
functions = [
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]},
},
"required": ["location"],
},
}
]
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613",
messages=messages,
functions=functions,
function_call="auto", # auto is default, but we'll be explicit
)The promise of the following libraries is that you don’t have to write such tedious extraction or function code. You can just write a simple pydantic model and get back structured data.
Structured Data
The other foundational tool at use in this tutorial is Pydantic.
Pydantic is a data validation library that uses Python type annotations to validate data. It allows you to create data models, and it will automatically validate that the incoming data matches the model. This can be incredibly useful when dealing with APIs or other data sources where you want to ensure the data is in the correct format before you start working with it.
Extracting Data with LLMs
Now that we covered the background. Let’s get started.
We’re going to be looking at three libraries that are all quite new and created within the last year.
The contenders are:
Let’s get started!
The contenders
Marvin
Marvin, as a library, has larger ambitions than just a data extraction library. In the creators’ words,
Marvin is a lightweight AI engineering framework for building natural language interfaces that are reliable, scalable, and easy to trust.
Sometimes the most challenging part of working with generative AI is remembering that it’s not magic; it’s software. It’s new, it’s nondeterministic, and it’s incredibly powerful - but still software.
Marvin’s goal is to bring the best practices for building dependable, observable software to generative AI. As the team behind Prefect, which does something very similar for data engineers, we’ve poured years of open-source developer tool experience and lessons into Marvin’s design.
At the time of this writing, Marvin, has a growing discord, is version 1.5.5 (and therefore ready for production). It also has the highest github stars of our contenders as well as the most forks.
Marvin is commercially backed by Prefect.
Overall, Marvin is a fairly simple feeling library. You’ll see that below.
Adoption Data / Community Data
- Discord = 432
- Version = 1.5.5
- Stars = ~3600
- forks =367
Instructor
Instructor is a library that helps get structured data out of LLMs. It has narrow dependencies and a simple API, requiring basic nothing sophisticated from the end user.
In the author’s words:
Instructorhelps to ensure you get the exact response type you’re looking for when using openai’s function call api. Once you’ve defined thePydanticmodel for your desired response,Instructorhandles all the complicated logic in-between - from the parsing/validation of the response to the automatic retries for invalid responses. This means that we can build in validators ‘for free’ and have a clear separation of concerns between the prompt and the code that calls openai.
The library is still early, version 0.2.9 has a modest star count (1300) but hits above it’s weight since it’s basically a single person working on it.
Now just because it’s one person doesn’t mean it’s bad. In fact, I found it to be very simple to use. It just means that from a long term maintenance perspective, it might be challenging. Something to note.
Adoption Data / Community Data
- Discord = NA
- Version = 0.2.9
- Stars = ~1300
- forks = 87
Guardrails AI
Guardrails is a project that appears to be backed by a company. The project, aptly named Guardrails, is centered around the following concept:
What is Guardrails?
Guardrails AI is an open-source library designed to ensure reliable interactions with Large Language Models (LLMs). It provides:
✅ A framework for creating custom validators ✅ Orchestration of prompting, verification, and re-prompting ✅ A library of commonly used validators for various use cases ✅ A specification language for communicating requirements to LLM
Guardrails shares a similar philosophy with Instructor and Marvin.
Guardrails AI enables you to define and enforce assurance for AI applications, from structuring output to quality controls. It achieves this by creating a ‘Guard’, a firewall-like bounding box around the LLM application, which contains a set of validators. A Guard can include validators from our library or a custom validator that enforces your application’s intended function.
- from the blog
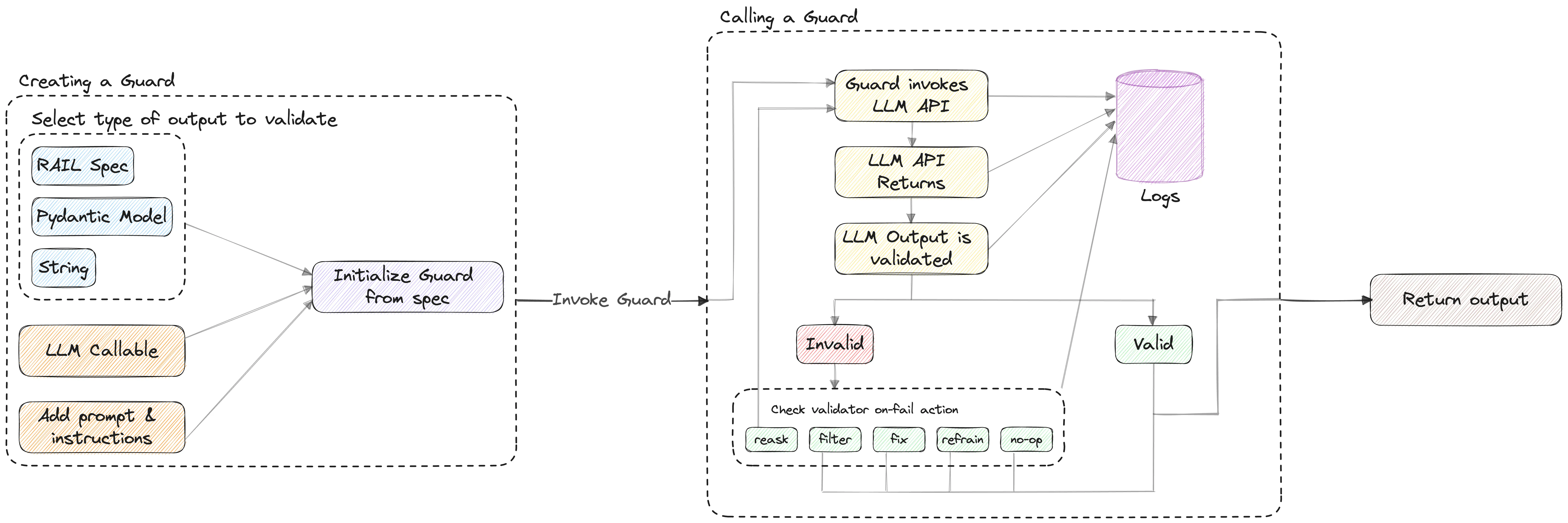
Currently, Guardrails is in beta and has not had a formal release, so it may not be suitable for production use cases.
However, Guardrails has a broader mission. They aim to create a “bounding box” around LLM apps to validate and ensure quality. They plan to achieve this by introducing a .RAIL file type, a dialect of XML. This ambitious approach extends beyond the simple concept of “using AI to extract data”.
Here’s their explanation of RAIL.
🤖 What is
RAIL?
.RAILis a dialect of XML, standing for “Reliable AI markup Language”. It can be used to define:
- The structure of the expected outcome of the LLM. (E.g. JSON)
- The type of each field in the expected outcome. (E.g. string, integer, list, object)
- The quality criteria for the expected outcome to be considered valid. (E.g. generated text should be bias-free, generated code should be bug-free)
- The corrective action to take in case the quality criteria is not met. (E.g. reask the question, filter the LLM, programmatically fix, etc.)
Warning…
Another challenge I had was the dependencies, Guardrails requires pydantic version 1.10.9. Pydantic’s latest version is v.2.4.1. This caused a number of issues for me during installation and I had to setup a dedicated environment for it. A challenge is that pydantic went through a ground up rewrite from version 1.10, so it may simply be challenging for them to rewrite everything.
Adoption Data / Community Data
- Discord = 689
- version = 0.2.4
- Stars = ~2400
- Forks = 158
The user experience
For this use case, the libraries are roughly equivalent.
You define a pydantic model.
Then you either:
- pass that directly into a monkey-patched openai function call (instructor),
- pass that into a wrapper function with the end function call that you want to make (guardrails), or
- use a python decorator function on your pydantic class and pass your function into that.
Let’s see them in action!
The test application - extracting data from a podcast transcript
I ran a simple test to compare these different extraction tools. I wanted to see how they would perform on a simple task - extracting data from a podcast transcript.
You could see this use case coming up for advertising, for market or competitive research, any number of things.
Pre-processing the data
The first thing we need to do is some basic pre-processing. We’ve done something similar in other tutorials, but we’ll do it again here.
First we get the podcast using the RSS feed.
import feedparser
podcast_atom_link = "https://api.substack.com/feed/podcast/1084089.rss" # latent space podcastbbbbb
parsed = feedparser.parse(podcast_atom_link)
episode = [ep for ep in parsed.entries if ep['title'] == "Why AI Agents Don't Work (yet) - with Kanjun Qiu of Imbue"][0]
episode_summary = episode['summary']
print(episode_summary[:100])<p><em>Thanks to the </em><em>over 11,000 people</em><em> who joined us for the first AI Engineer SuNow we parse the HTML.
from unstructured.partition.html import partition_html
parsed_summary = partition_html(text=''.join(episode_summary))
start_of_transcript = [x.text for x in parsed_summary].index("Transcript") + 1
print(f"First line of the transcript: {start_of_transcript}")
text = '\n'.join(t.text for t in parsed_summary[start_of_transcript:])
text = text[:3508] # shortening the transcript for speed & costFirst line of the transcript: 58Running Extraction with Instructor
Now let’s run the code with Instructor. If you want to follow along with the full tutorial, check out the code on the full extraction tutorial.
from pydantic import BaseModel
from typing import Optional, List
from pydantic import Field
class Person(BaseModel):
name: str
school: Optional[str] = Field(..., description="The school this person attended")
company: Optional[str] = Field(..., description="The company this person works for ")
class People(BaseModel):
people: List[Person]import openai
import instructor
instructor.patch()response = openai.ChatCompletion.create(
model="gpt-4",
response_model=People,
messages=[
{"role": "user", "content": text},
]
)
print(response)people=[Person(name='Alessio', school=None, company='Decibel Partners'), Person(name='Swyx', school=None, company='Smol.ai'), Person(name='Kanjun', school='MIT', company='Imbue'), Person(name='Josh', school=None, company='Imbue')]Overall the result is high quality, we’ve gotten all the names and companies.
class Company(BaseModel):
name:str
class ResearchPaper(BaseModel):
paper_name:str = Field(..., description="an academic paper reference discussed")
class ExtractedInfo(BaseModel):
people: List[Person]
companies: List[Company]
research_papers: Optional[List[ResearchPaper]]
response = openai.ChatCompletion.create(
model="gpt-4",
response_model=ExtractedInfo,
messages=[
{"role": "user", "content": text},
]
)
print(response)people=[Person(name='Alessio', school=None, company='Decibel Partners'), Person(name='Swyx', school=None, company='Smol.ai'), Person(name='Kanjun', school='MIT', company='Imbue'), Person(name='Josh', school=None, company='Ember')] companies=[Company(name='Decibel Partners'), Company(name='Smol.ai'), Company(name='Imbue'), Company(name='Generally Intelligent'), Company(name='Ember'), Company(name='Sorceress'), Company(name='Dropbox'), Company(name='MIT Media Lab'), Company(name='OpenA')] research_papers=NoneYou can see how well this works, to grab a whole bunch of structured data for us with basically no work. Right now we’re just working on a excerpt of this data, but with basically zero NLP specific work, we’re able to get some pretty powerful results.
Running Extraction with Marvin
Now let’s run the code with Marvin. If you want to follow along with the full tutorial, check out the code on the full extraction tutorial.
!python --versionPython 3.11.5import pydantic
print(pydantic.__version__)
import marvin
print(marvin.__version__)2.4.2
1.5.5from dotenv import load_dotenv
load_dotenv()Truefrom marvin import ai_model
from pydantic import BaseModel
from typing import Optional, List
from pydantic import Field
class Person(BaseModel):
name: str
school: Optional[str] = Field(..., description="The school this person attended")
company: Optional[str] = Field(..., description="The company this person works for")
@ai_model
class People(BaseModel):
people: List[Person]
People(text)People(people=[Person(name='Alessio', school=None, company='Residence at Decibel Partners'), Person(name='Swyx', school=None, company='Smol.ai'), Person(name='Kanjun', school='MIT', company='Imbue'), Person(name='Josh', school=None, company=None)])class Company(BaseModel):
name:str
class ResearchPaper(BaseModel):
paper_name:str = Field(..., description="an academic paper reference discussed")
@ai_model(instructions="Get the following information from the text")
class ExtractedInfo(BaseModel):
people: List[Person]
companies: List[Company]
research_papers: Optional[List[ResearchPaper]]
ExtractedInfo(text)ExtractedInfo(people=[Person(name='Alessio', school=None, company='Residence at Decibel Partners'), Person(name='Swyx', school=None, company='Smol.ai'), Person(name='Kanjun', school='MIT', company='Imbue')], companies=[Company(name='Decibel Partners'), Company(name='Smol.ai'), Company(name='Imbue'), Company(name='Generally Intelligent'), Company(name='Ember'), Company(name='Sorceress')], research_papers=None)Note: What’s interesting is that if you don’t supply the instructions you won’t get as strong of results. I started off with instructions blank and got poor results. When I did the same with instructor, it worked fine.
Changing the decorator instructions gave me better results. This is also allows you to configure th LLM as well as temperature and more.
Running Extraction with Guardrails AI
Now let’s run the code with Marvin. If you want to follow along with the full tutorial, check out the code on the full extraction tutorial.
import guardrails as gd
from pydantic import BaseModel
from typing import Optional, List
from pydantic import Field
class Person(BaseModel):
name: str
school: Optional[str] = Field(..., description="The school this person attended")
company: Optional[str] = Field(..., description="The company this person works for")
class People(BaseModel):
people: List[Person]
guard = gd.Guard.from_pydantic(output_class=People, prompt="Get the following objects from the text:\n\n ${text}")import openai
import os
raw_llm_output, validated_output = guard(
openai.ChatCompletion.create,
prompt_params={"text": text},
)
print(validated_output){'people': [{'name': 'Alessio', 'school': 'Residence at Decibel Partners', 'company': 'CTO'}, {'name': 'Swyx', 'school': 'Smol.ai', 'company': 'founder'}, {'name': 'Kanjun', 'school': 'Imbue', 'company': 'founder'}]}class Company(BaseModel):
name:str
class ResearchPaper(BaseModel):
paper_name:str = Field(..., description="an academic paper reference discussed")
class ExtractedInfo(BaseModel):
people: List[Person]
companies: List[Company]
research_papers: Optional[List[ResearchPaper]]
guard = gd.Guard.from_pydantic(output_class=ExtractedInfo, prompt="Get the following objects from the text:\n\n ${text}")
raw_llm_output, validated_output = guard(
openai.ChatCompletion.create,
prompt_params={"text": text},
)
print(validated_output)/Users/williamchambers/miniconda3/envs/guardrails-extract/lib/python3.9/site-packages/guardrails/prompt/instructions.py:32: UserWarning: Instructions do not have any variables, if you are migrating follow the new variable convention documented here: https://docs.getguardrails.ai/0-2-migration/
warn(
/Users/williamchambers/miniconda3/envs/guardrails-extract/lib/python3.9/site-packages/guardrails/prompt/prompt.py:23: UserWarning: Prompt does not have any variables, if you are migrating follow the new variable convention documented here: https://docs.getguardrails.ai/0-2-migration/
warnings.warn(
incorrect_value={'people': [{'name': 'Alessio', 'school': 'Decibel Partners', 'company': 'CTO'}, {'name': 'Swyx', 'school': 'Smol.ai', 'company': 'founder'}, {'name': 'Kanjun', 'school': 'Imbue', 'company': 'founder'}], 'companies': [{'name': 'Decibel Partners'}, {'name': 'Residence'}, {'name': 'Smol.ai'}, {'name': 'Imbue'}]} fail_results=[FailResult(outcome='fail', metadata=None, error_message='JSON does not match schema', fix_value=None)]Note: The result failed to parse, while the other two libraries succeeded just fine. It might be in the implementation or might be a bug in this version, but it didn’t work out of the box.
So which library should you choose?
Overall these libraries, at this level, feel similar. They’re trying to do the same basic thing and accomplish that.
If I had to recommend one, I would recommend Marvin. It’s simple, it has a coherent API and it feels “fluid” to use. It’s also got commercial backing from an established company so it’s not likely to go anywhere immediately. That doesn’t always mean success, but it’s at least a reasonable sign that the library will be around for a while.
If you’re just trying to get something out the door, then choose Marvin.
If this is a domain you’re expected to spend a lot of time on, then it’s worth at least looking at the other libraries. Guardrails, with their RAIL abstraction is trying to do a lot more than be a framework for AI engineering - they’re trying to approach the ‘structured LLM’ with a fresh vision. This ambition means that there’s likely a lot more to come from this team and this project, it’s just too early to see that.
In short…
- 🏆Winner🏆 - Simplest: Instructor - instructors simple API means that there’s not a lot of moving parts and it’s simple to understand and get started. There’s a lot of complexity that you can achieve with these simple building blocks.
- 🏆Winner🏆 - Most General: Ask Marvin - Ask Marvin seems like a great library. It’s got tools for extraction, for classificaiton, for complex business logic and flows, and even more larger AI applications. It’s a bright spot in the AI ecosystem and while it doesn’t have the mega-hype of some other libraries like Langchain, it does have immense potential in my eyes.
- 🏆Winner🏆 - Long Term Focused: Guardrails AI - Guardrails was the hardest library to get started, but they seem the most focused on extraction. Their ambition of creating a language / DSL for wrapping LLM API calls is an ambitious vision and I hope that we get to see more from the team. I found the library to be a little challenging to use and it took me, by far, the longest to figure out how to effectively use it. The examples are a little dated and I wasn’t able to figure out how to configure the model. On top of that, it failed with the second example that I provided all of the models - which was a little disappointing.
Key Considerations
Some key considerations for you and your use case:
- Cost Effectiveness: Consider the cost of using these libraries. Are they cost-effective for your specific use case? Remember, the cost of using AI models can add up quickly, so it’s important to evaluate this aspect.
- Value of Prediction: What is the value of the prediction to your business? Is using an LLM for extraction a viable business strategy for you? This will largely depend on the nature of your business and the specific use case.
- Batching Predictions: Can you batch multiple predictions into one to save on the number of tokens and cost? Batching predictions can be a cost-effective strategy, especially for larger projects.
Final thoughts
In conclusion, this tutorial took you through a couple of different LLM-based data extraction libraries. We hope you’ve learned a lot more about how to use different libraries in the space and hope you can choose one that makes sense for you!