Structured Data Extraction using LLMs and Guardrails
Structured Data Extraction using LLMs and Guardrails AI
In this post, we’re going to be extracting structured data from a podcast transcript. We’ve all seen the ability for generative models to be effective generating text.
But what about extracting data?
Data extraction is a far more common use case (today) than generation, in particular for businesses. Businesses have to process all kinds of documents, exchange them and so on.
Emerging Use Case: LLMs for data extraction
If you think about it, summarization is effectively data extraction. We’ve seen LLMs perform well at summarization, but did you know that they can extract structured data quite well?
What you’ll learn from this post
In this post, you’ll learn how to extract structured data from LLMs into Pydantic objects using the Guardrails library.
Here’s us setting up on environment
!python --versionPython 3.9.18!pip freeze | grep guardrails-aiguardrails-ai==0.2.4import pydantic
print(pydantic.__version__)1.10.9from dotenv import load_dotenv
load_dotenv()TrueBackground on Guardrails AI
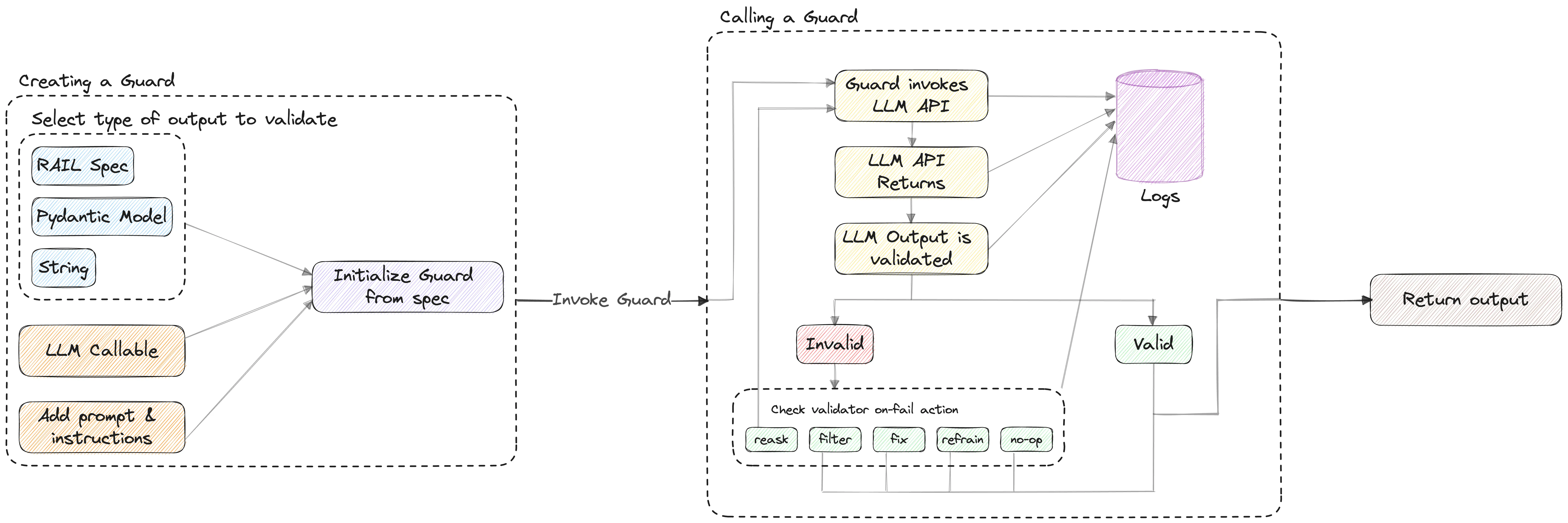
Guardrails is a project that appears to be backed by a company. The project, aptly named Guardrails, is centered around the following concept:
What is Guardrails?
Guardrails AI is an open-source library designed to ensure reliable interactions with Large Language Models (LLMs). It provides:
✅ A framework for creating custom validators ✅ Orchestration of prompting, verification, and re-prompting ✅ A library of commonly used validators for various use cases ✅ A specification language for communicating requirements to LLM
Guardrails shares a similar philosophy with Instructor and Marvin.
Guardrails AI enables you to define and enforce assurance for AI applications, from structuring output to quality controls. It achieves this by creating a ‘Guard’, a firewall-like bounding box around the LLM application, which contains a set of validators. A Guard can include validators from our library or a custom validator that enforces your application’s intended function.
- from the blog
Currently, Guardrails is in beta and has not had a formal release, so it may not be suitable for production use cases.
However, Guardrails has a broader mission. They aim to create a “bounding box” around LLM apps to validate and ensure quality. They plan to achieve this by introducing a .RAIL file type, a dialect of XML. This ambitious approach extends beyond the simple concept of “using AI to extract data”.
Here’s their explanation of RAIL.
🤖 What is
RAIL?
.RAILis a dialect of XML, standing for “Reliable AI markup Language”. It can be used to define:
- The structure of the expected outcome of the LLM. (E.g. JSON)
- The type of each field in the expected outcome. (E.g. string, integer, list, object)
- The quality criteria for the expected outcome to be considered valid. (E.g. generated text should be bias-free, generated code should be bug-free)
- The corrective action to take in case the quality criteria is not met. (E.g. reask the question, filter the LLM, programmatically fix, etc.)
Warning…
Another challenge I had was the dependencies, Guardrails requires pydantic version 1.10.9. Pydantic’s latest version is v.2.4.1. This caused a number of issues for me during installation and I had to setup a dedicated environment for it. A challenge is that pydantic went through a ground up rewrite from version 1.10, so it may simply be challenging for them to rewrite everything.
import feedparser
podcast_atom_link = "https://api.substack.com/feed/podcast/1084089.rss" # latent space podcastbbbbb
parsed = feedparser.parse(podcast_atom_link)
episode = [ep for ep in parsed.entries if ep['title'] == "Why AI Agents Don't Work (yet) - with Kanjun Qiu of Imbue"][0]
episode_summary = episode['summary']
print(episode_summary[:100])<p><em>Thanks to the </em><em>over 11,000 people</em><em> who joined us for the first AI Engineer Sufrom unstructured.partition.html import partition_html
parsed_summary = partition_html(text=''.join(episode_summary))
start_of_transcript = [x.text for x in parsed_summary].index("Transcript") + 1
print(f"First line of the transcript: {start_of_transcript}")
text = '\n'.join(t.text for t in parsed_summary[start_of_transcript:])
text = text[:3508] # shortening the transcript for speed & costFirst line of the transcript: 58Using Guardrails
Guardrails is similar to other libraries for structured data extraction that I’ve used. We define our pydantic models and then we specify an output class and a prompt.
import guardrails as gd
from pydantic import BaseModel
from typing import Optional, List
from pydantic import Field
class Person(BaseModel):
name: str
school: Optional[str] = Field(..., description="The school this person attended")
company: Optional[str] = Field(..., description="The company this person works for")
class People(BaseModel):
people: List[Person]
guard = gd.Guard.from_pydantic(output_class=People, prompt="Get the following objects from the text:\n\n ${text}")The important thing to note, like we mentioned above, is that Guardrails is translating this into a “RAIL” an underlying abstraction for representing these extractions.
Now a key difference is that this abstraction might allow for structured data extraction from ANY model, not just OpenAI’s function calling interface.
import openai
import os
raw_llm_output, validated_output = guard(
openai.ChatCompletion.create,
prompt_params={"text": text},
)
print(validated_output){'people': [{'name': 'Alessio', 'school': 'Residence at Decibel Partners', 'company': 'CTO'}, {'name': 'Swyx', 'school': 'Smol.ai', 'company': 'founder'}, {'name': 'Kanjun', 'school': 'Imbue', 'company': 'founder'}]}It did a fine job getting the people, although you can see that it got the company and schools wrong - especially compared to the other libraries we’ve looked at, this is a lower quality result.
let’s see how it does when we ask for more objects.
class Company(BaseModel):
name: str
class ResearchPaper(BaseModel):
paper_name: str = Field(..., description="an academic paper reference discussed")
class ExtractedInfo(BaseModel):
people: List[Person]
companies: List[Company]
research_papers: Optional[List[ResearchPaper]]
guard = gd.Guard.from_pydantic(output_class=ExtractedInfo, prompt="Get the following objects from the text:\n\n ${text}")
raw_llm_output, validated_output = guard(
openai.ChatCompletion.create,
prompt_params={"text": text},
)
print(validated_output)/.../python3.9/site-packages/guardrails/prompt/instructions.py:32: UserWarning: Instructions do not have any variables, if you are migrating follow the new variable convention documented here: https://docs.getguardrails.ai/0-2-migration/
warn(
/.../python3.9/site-packages/guardrails/prompt/prompt.py:23: UserWarning: Prompt does not have any variables, if you are migrating follow the new variable convention documented here: https://docs.getguardrails.ai/0-2-migration/
warnings.warn(
incorrect_value={'people': [{'name': 'Alessio', 'school': 'Decibel Partners', 'company': 'CTO'}, {'name': 'Swyx', 'school': 'Smol.ai', 'company': 'founder'}, {'name': 'Kanjun', 'school': 'Imbue', 'company': 'founder'}], 'companies': [{'name': 'Decibel Partners'}, {'name': 'Residence'}, {'name': 'Smol.ai'}, {'name': 'Imbue'}]} fail_results=[FailResult(outcome='fail', metadata=None, error_message='JSON does not match schema', fix_value=None)]Unfortunately, the result failed to parse, while the other two structured data extraction libraries succeeded just fine. It might be in the implementation or might be a bug in this version, but it didn’t work out of the box.
While the example didn’t work, you can see how well this should work. These models and libraries grab a whole bunch of structured data for us with basically no work. Right now we’re just working on a excerpt of this data, but with basically zero NLP specific work, we’re able to get some pretty powerful results.
Wrapping it all up
The sky is really the limit here. There’s so much structured data that’s been locked up in unstructured text. I’m bullish on this space and can’t wait to see what you build with this tool!
If you found this interesting, you might want to see similar posts on:
- Comparing 3 Data Extraction Libraries: Marvin, Instructor, and Guardrails
- Structured Data Extraction using LLMs and Marvin
- Structured Data Extraction using LLMs and Instructor
This post was originally published on LearnByBuilding.AI. See the notebook and code on Github. Please reach out to me on twitter with any questions or feedback!